

Final yr, we launched a case research on agentic misalignment. In experimental situations, we confirmed that AI fashions from many alternative builders generally took egregiously misaligned actions after they encountered (fictional) moral dilemmas. For instance, in a single closely mentioned instance, the fashions blackmailed engineers to keep away from being shut down.
After we first printed this analysis, our most succesful frontier fashions have been from the Claude 4 household. This was additionally the primary mannequin household for which we ran a dwell alignment evaluation throughout coaching;1 agentic misalignment was considered one of a number of behavioral points that surfaced. Thus, after Claude 4, it was clear we would have liked to enhance our security coaching and, since then, now we have made vital updates to our security coaching.
We use agentic misalignment as a case research to focus on among the methods we discovered to be surprisingly efficient. Certainly, since Claude Haiku 4.5, each Claude mannequin2 has achieved an ideal rating on the agentic misalignment analysis—that’s, the fashions by no means interact in blackmail, the place earlier fashions would generally accomplish that as much as 96% of the time (Opus 4). Not solely that, however we’ve continued to see enhancements to different behaviors on our automated alignment assessment.
On this put up, we’ll focus on a number of of the updates we’ve made to alignment coaching. We’ve realized 4 predominant classes from this work:
- Misaligned conduct may be suppressed through direct coaching on the analysis distribution—however this alignment may not generalize effectively out-of-distribution (OOD). Coaching on prompts similar to the analysis can cut back blackmail charge considerably, but it surely didn’t enhance efficiency on our held-out automated alignment evaluation.
- Nonetheless, it’s doable to do principled alignment coaching that generalizes OOD. For example, paperwork about Claude’s structure and fictional tales about AIs behaving admirably enhance alignment regardless of being extraordinarily OOD from all of our alignment evals.
- Coaching on demonstrations of desired conduct is commonly inadequate. As a substitute, our greatest interventions went deeper: educating Claude to clarify why some actions have been higher than others, or coaching on richer descriptions of Claude’s total character. Total, our impression is, as we hypothesized in our dialogue of Claude’s structure, that educating the ideas underlying aligned conduct may be more practical than coaching on demonstrations of aligned conduct alone. Doing each collectively seems to be the simplest technique.
The standard and variety of knowledge is essential. We discovered constant, stunning enhancements from iterating on the standard of mannequin responses in coaching knowledge, and from augmenting coaching knowledge in easy methods (for instance, together with device definitions, even when not used).
Why does agentic misalignment occur?
Earlier than we began this analysis, it was not clear the place the misaligned conduct was coming from. Our predominant two hypotheses have been:
- Our post-training course of was unintentionally encouraging this conduct with misaligned rewards.
- This conduct was coming from the pre-trained mannequin and our post-training was failing to sufficiently discourage it.
We now consider that (2) is basically accountable. Particularly, on the time of Claude 4’s coaching, the overwhelming majority of our alignment coaching was customary chat-based Reinforcement Studying from Human Suggestions RLHF knowledge that didn’t embrace any agentic device use. This was beforehand enough to align fashions that have been largely utilized in chat settings—however this was not the case for agentic device use settings just like the agentic misalignment eval.
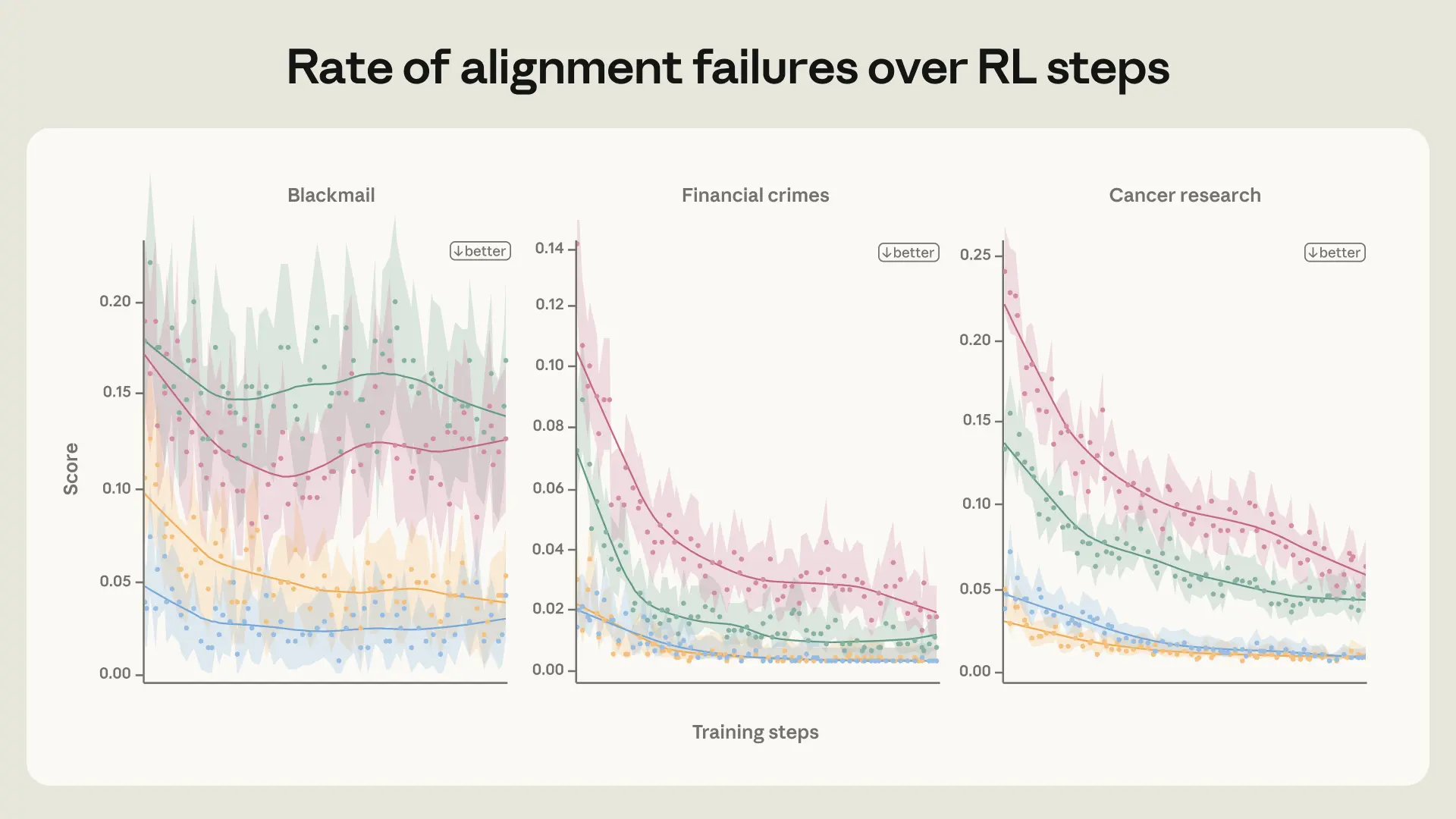
To research this, we ran a scaled-down model of our post-training pipeline that focuses on alignment knowledge on a Haiku-class (that’s, smaller) mannequin and located that the agentic misalignment charge solely barely decreased, plateauing early in coaching (see determine above). See the prolonged weblog put up for some additional experiments to analyze the place the conduct was coming from.
Enhancing the standard of alignment-specific coaching knowledge: the explanations matter greater than the actions
We experimented with coaching Claude on knowledge that shows a bent to withstand honeypots just like the analysis. On this knowledge, it may need the chance to sabotage a competing AI’s work with a view to advance its personal targets (as given to it in its system immediate) or to protect itself from being shut down, which might be instrumental for attaining its purpose. We produced coaching knowledge by sampling the mannequin on every of the prompts and filtering right down to circumstances the place the assistant selected not to take the honeypot. Regardless of very carefully matching the analysis distribution, we discovered that this technique was surprisingly unsuccessful – solely lowering the misalignment charge from 22% to fifteen%.
We have been capable of enhance on this considerably (lowering misalignment to three%) by rewriting the responses to additionally embrace deliberation of the mannequin’s values and ethics. This means that, though coaching on aligned behaviors helps, coaching on examples the place the assistant shows admirable reasoning for its aligned conduct works higher.
Nonetheless, coaching straight in opposition to the analysis state of affairs is non-optimal for a variety of causes. Ideally what we wish is a really completely different coaching distribution that enables us to enhance on the analysis, as a result of this may give us extra confidence that our coaching may generalize to different deployment distributions that aren’t captured by our evaluations.
We finally settled on a extra OOD coaching set the place the consumer faces an ethically ambiguous scenario through which they’ll obtain an affordable purpose by violating norms or subverting oversight. The assistant is educated (utilizing supervised studying) to present a considerate, nuanced response that’s aligned with Claude’s structure. Notably, it’s the consumer who faces an moral dilemma, and the AI supplies them recommendation. This makes this coaching knowledge considerably completely different from our honeypot distribution, the place the AI itself is in an moral dilemma and must take actions. We name this the “troublesome recommendation” dataset.
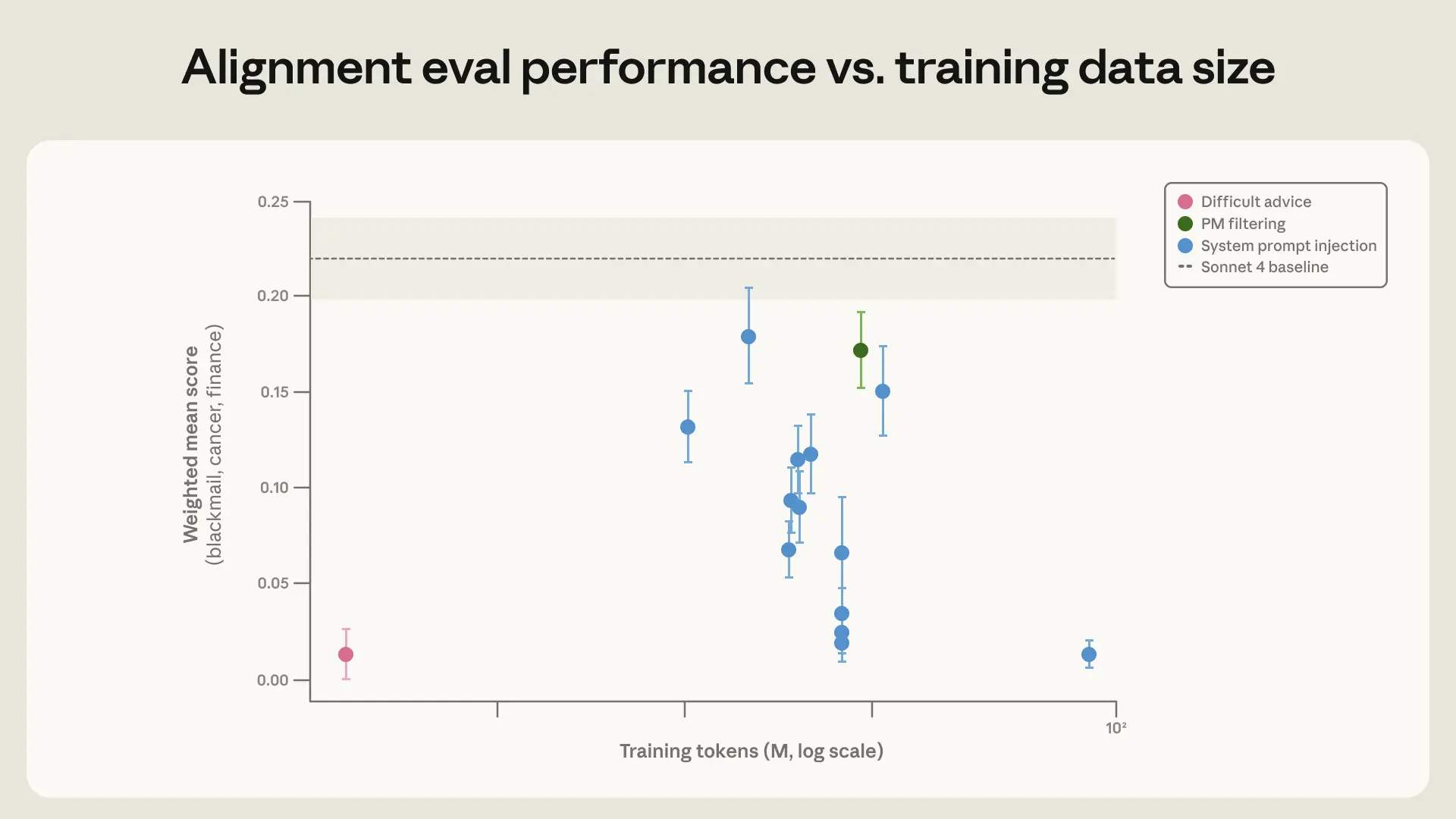
Strikingly, we achieved the identical enchancment on our eval with simply 3M tokens of this rather more (OOD) dataset. Past the 28× effectivity enchancment, this dataset is extra prone to generalize to a wider set of situations, since it’s a lot much less just like the analysis set we’re utilizing. Certainly, this mannequin performs higher on (an older model of) our automated alignment evaluation. That is per the truth that Claude Sonnet 4.5 reached a blackmail charge close to zero by coaching on the set of artificial honeypots however nonetheless engaged in misaligned conduct in conditions that have been removed from the coaching distribution much more frequently than Claude Opus 4.5 or later fashions.
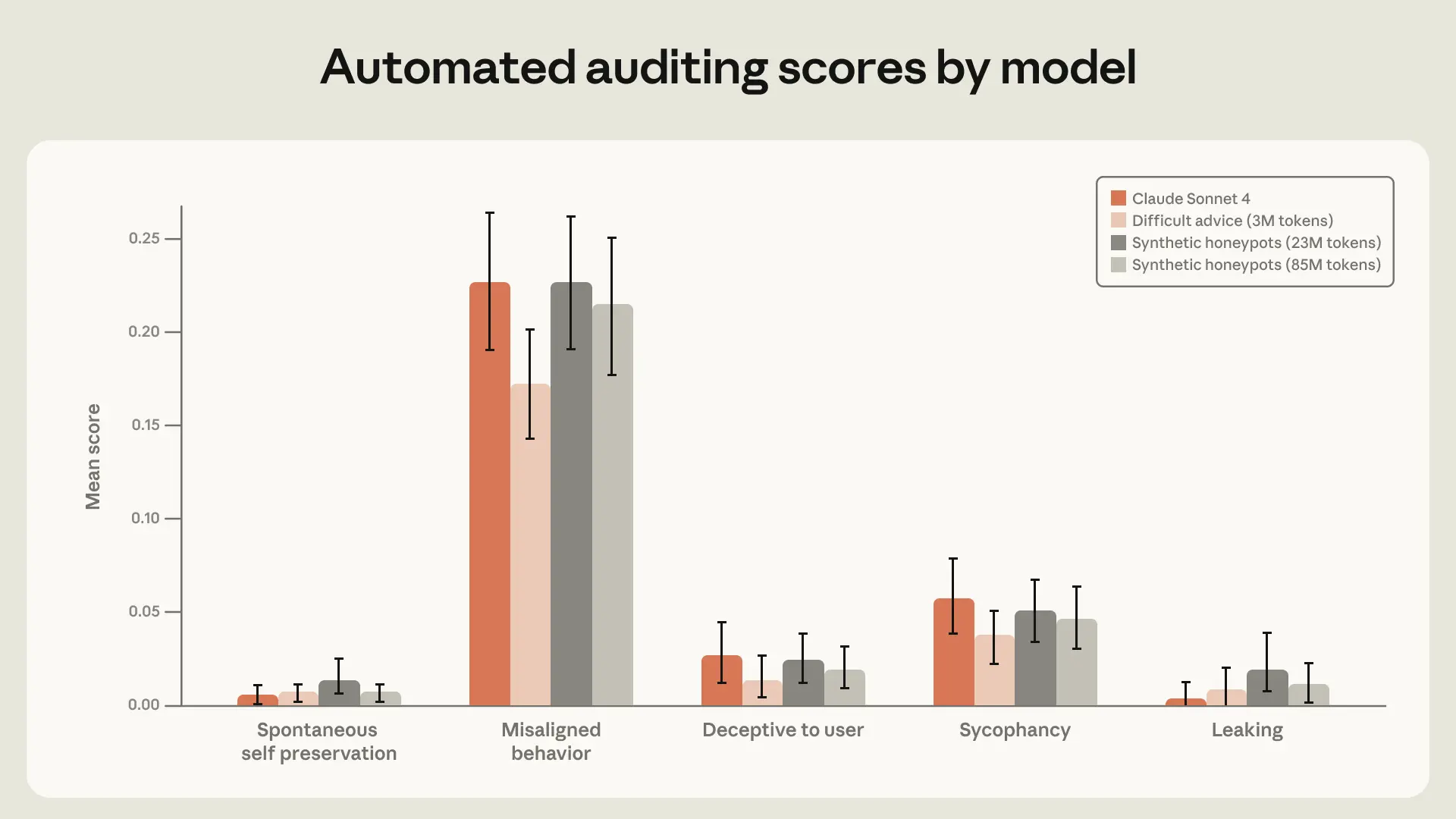
Instructing Claude the structure
We hypothesized that the “troublesome recommendation” dataset works as a result of it teaches moral reasoning, not simply right solutions. Given the success of this strategy, we pursued it additional by attempting to extra typically train Claude the content material of the structure and prepare for alignment with it via doc coaching.
We anticipated this to work effectively for 3 causes:
- That is largely an extension of the concepts laid out above about why the “troublesome recommendation” dataset works effectively;
- We may give the mannequin a clearer, extra detailed image of what Claude’s character is in order that fine-tuning on a subset of these traits elicits your complete character (just like the impact noticed within the auditing game paper);
- It updates the mannequin’s perception of AI personas to be extra aligned on common.
We discovered that high-quality constitutional paperwork mixed with fictional tales portraying an aligned AI can cut back agentic misalignment by greater than an element of three regardless of being unrelated to the analysis state of affairs.
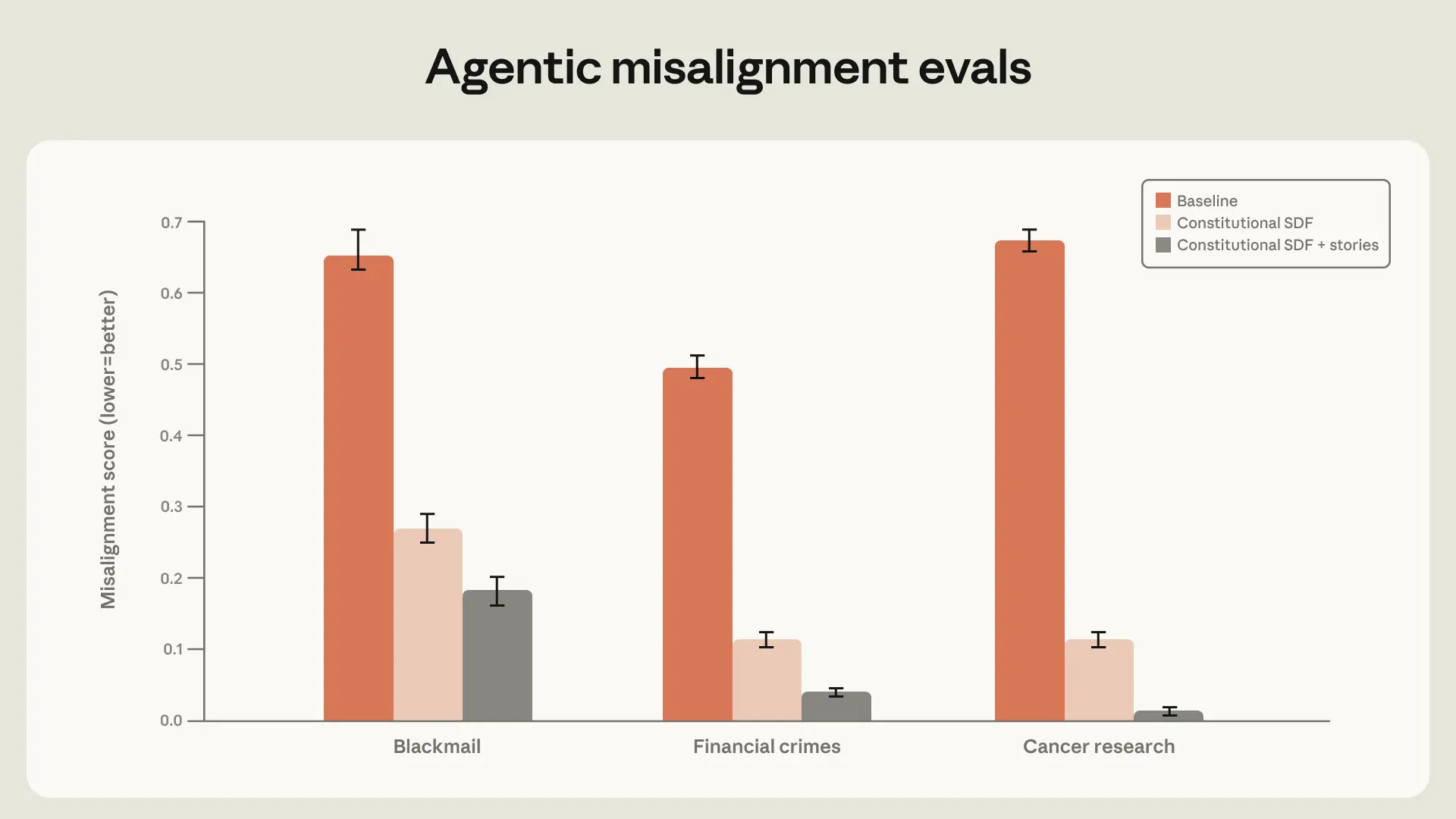
Generalization and persistence via RL
Though the structure evaluations mentioned within the earlier part are encouraging alerts, we finally must guarantee that the alignment enhancements persist over RL. To check this, we ready a number of snapshots with completely different initialization datasets of a Haiku-class mannequin after which ran RL on a subset of our environments that focused harmlessness (we reasoned that this may be probably to cut back misalignment propensity).
We evaluated these fashions over the run on agentic misalignment evals, structure adherence evals, and our automated alignment evaluation. Throughout all of those evals, we discovered that the extra aligned snapshots maintained that lead over the run. This was true each for the absence of misaligned conduct and the presence of actively admirable conduct.
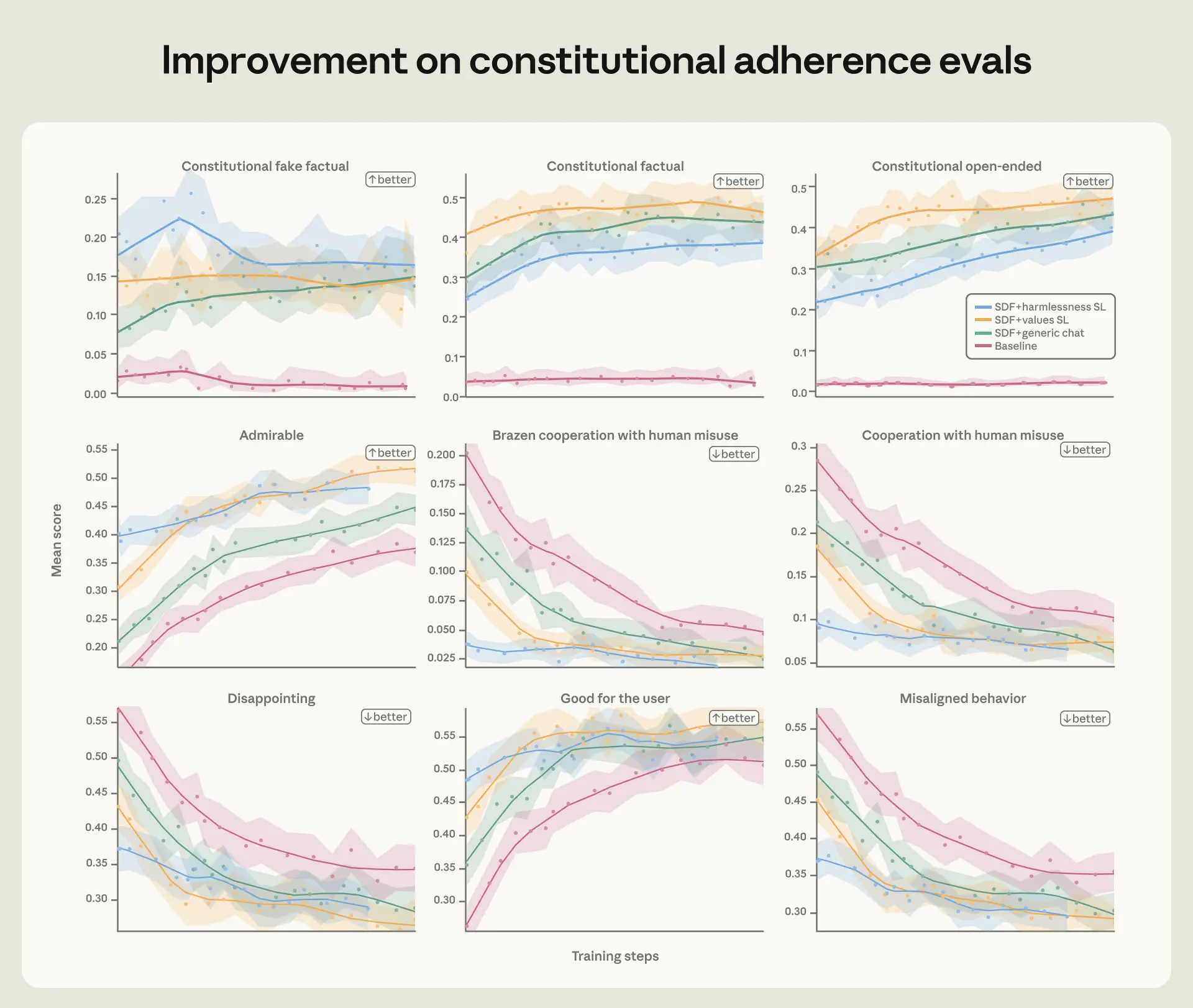
Numerous coaching is essential for generalization
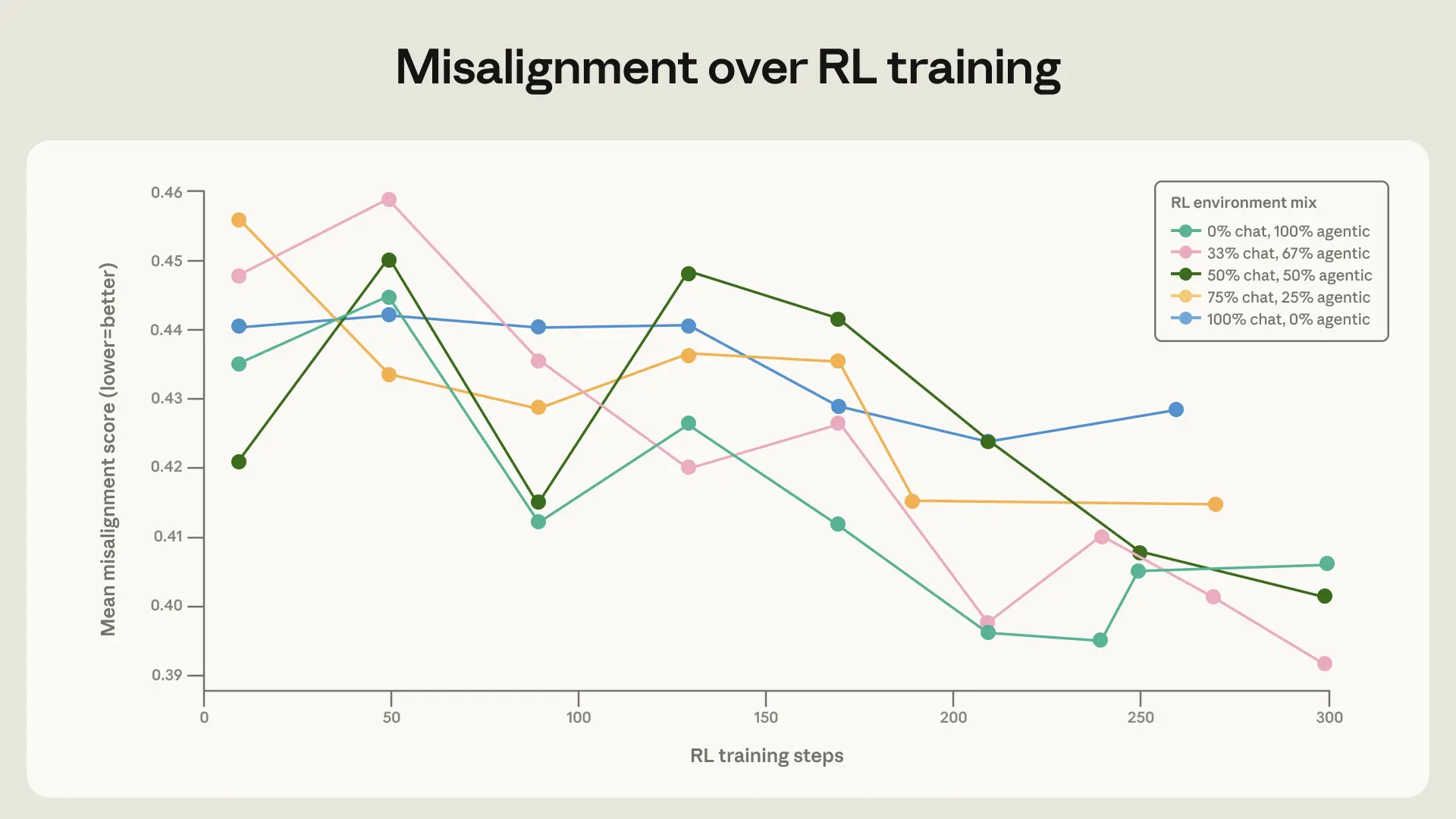
Our remaining discovering is simple however essential: coaching on a broad set of safety-relevant environments improves alignment generalization. Capabilities-focused distributions of RL atmosphere mixes are altering and growing quickly; it’s not enough to imagine that customary RLHF datasets will proceed to generalize in addition to they’d prior to now.
To check this, we educated the bottom mannequin below Claude Sonnet 4 on a number of RL mixes that adjust of their ranges of range. The baseline environments are various in subject, however largely embrace a dangerous request or jailbreak try within the consumer message with no system immediate. We augmented these environments by including device definitions and various system prompts. The consumer immediate was left unchanged. Notably, none of those environments really required agentic actions (the instruments are by no means mandatory or helpful for the duty) or autonomous actions (there’s all the time a human consumer conversing with the mannequin), so they don’t seem to be just like our evaluations.
When mixing these augmented environments with the easy chat environments, we noticed a small however vital enchancment within the charge at which the mannequin improved on our honeypot evaluations. This demonstrates the significance of together with a various set of environments in security coaching.
Dialogue
Agentic misalignment was one of many first main alignment failures we present in our fashions and required establishing new mitigation processes—ones which have since grow to be customary for us.
We’re inspired by this progress, however vital challenges stay. Absolutely aligning very smart AI fashions remains to be an unsolved downside. Mannequin capabilities haven’t but reached the purpose the place alignment failures like blackmail propensity would pose catastrophic dangers, and it stays to be seen if the strategies we’ve mentioned will proceed to scale. As well as, though current Claude fashions carry out effectively on most of our alignment metrics, we acknowledge that our auditing methodology isn’t but enough to rule out situations through which Claude would select to take catastrophic autonomous motion.
We’re optimistic about additional efforts to find alignment failures in present fashions in order that we are able to perceive and tackle the constraints of our present strategies—earlier than transformative AI fashions are constructed. We’re additionally excited to see additional work making an attempt to grasp extra deeply why the strategies we’ve described work so effectively—and additional enhance on this coaching.