


In relation to bringing superior AI to the sting, Google AI Edge’s LiteRT-LM delivers one of the highly effective and optimized experiences for deploying Gemma 4 throughout platforms. Leveraging LiteRT (previously TensorFlow Lite) for inference, LiteRT-LM empowers native AI throughout a large number of Google merchandise—together with Chrome, ChromeOS, the Pixel Watch, and the current viral Google AI Edge Gallery app (Android / iOS). From unlocking state-of-the-art agentic capabilities with Gemma 4 to scaling our demanding manufacturing use instances, this confirmed engine is now able to energy your personal purposes. Learn on for a deep dive into the underlying stack and the way you should utilize LiteRT-LM on your personal edge LLM deployments.
State-of-the-art efficiency
To totally unlock Gemma 4 on-device, we leverage the Google AI Edge stack, essentially the most performant strategy to run Gemma 4 throughout platforms (for even better efficiency, Gemma 4 will be run as system-service through Android AICore). To navigate the competing calls for of restricted reminiscence, restricted compute, and fragmented {hardware}, this stack helps superior quantization schemes alongside a basis of accelerated XNNPACK and MLDrift kernels. By coupling this environment friendly footprint with the LiteRT runtime, the stack unlocks seamless mannequin execution and broad portability throughout CPU, GPU, and NPU backends. Lastly, on the orchestration layer, LiteRT-LM makes use of optimized pipelines to keep away from pricey CPU/GPU information transfers, alongside Multi-Token Prediction (MTP) and superior session administration. Collectively, this whole integration supplies the highest-performing runtime atmosphere for Gemma fashions.
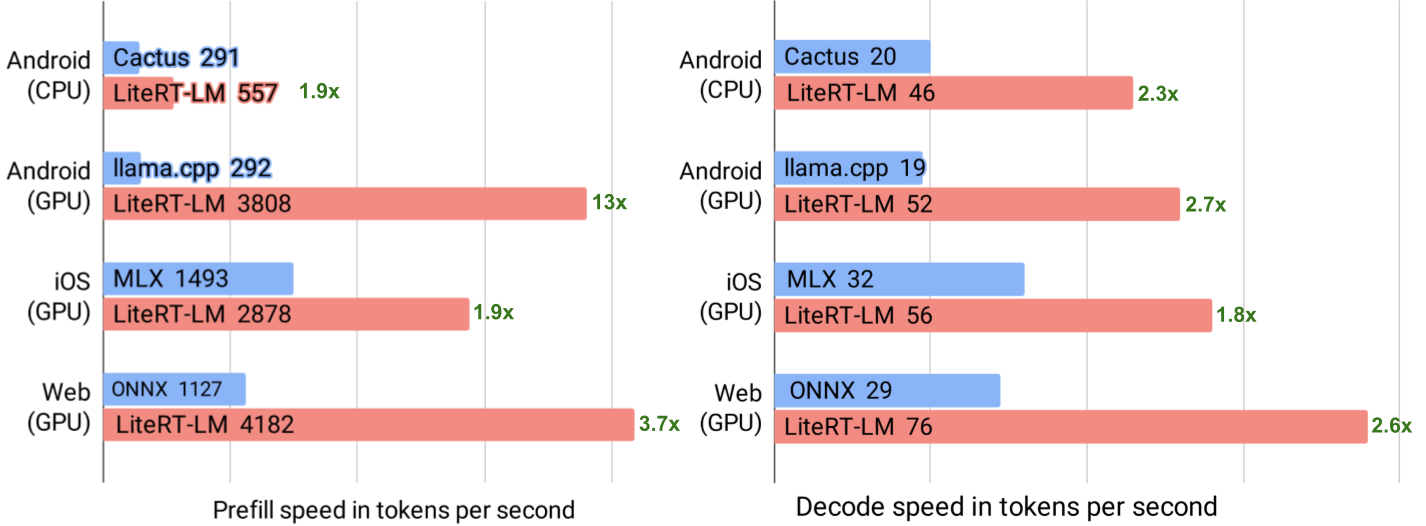
LiteRT-LM prefill and decode efficiency operating Gemma 4 E2B
(Android: Samsung S26 Extremely, iOS: iPhone 17 Professional, Internet: Chrome on a MacBook Professional 2024 with Apple M4 Max).
Constructed for pace throughout {hardware} backends and platforms
LiteRT-LM is engineered to ship distinctive efficiency throughout your entire edge ecosystem, guaranteeing low-latency inference on Android, iOS, and the open net. To realize this, the runtime supplies essentially the most optimum {hardware} backend optimizations by way of LiteRT, seamlessly accelerating workloads through CPU, GPU, and NPU (at present on Android). This method permits builders to construct as soon as and obtain peak efficiency in all places:
- When operating Gemma 4 E2B with out MTP enabled, LiteRT-LM achieves a formidable 52 tokens/sec decode pace through the GPU backend on Android (OpenCL), and 56 tokens/sec on iOS (Steel).
- On the internet, utilizing WebGPU, builders can anticipate decode speeds of as much as 76 tokens/sec decode on a Macbook Professional, proving that state-of-the-art on-device AI is now a actuality whatever the person’s platform or {hardware}.
Multi-Token Prediction (MTP) for peak throughput
Probably the most vital efficiency milestones within the LiteRT-LM pipeline is our native assist for the Multi-Token Prediction (MTP) drafters recently launched with the Gemma 4 mannequin household. By integrating this specialised speculative decoding structure, LiteRT-LM bypasses conventional latency bottlenecks to ship as much as a 2.2x speedup.
Customary LLM inference is basically memory-bandwidth sure; processors spend nearly all of their time transferring billions of parameters from VRAM to compute items simply to generate a single token. Whereas speculative decoding mitigates this, naive implementations can introduce new bottlenecks. LiteRT-LM prevents this by optimizing the information interaction between the first Gemma 4 mannequin and the MTP drafter.
To realize this, LiteRT-LM enforces reminiscence locality by executing each the light-weight MTP drafter and the first mannequin on the identical {hardware} IP (e.g., the GPU). Managing the shared KV cache and activations inside native reminiscence totally eliminates the latency penalties of cross-IP synchronization and information transfers. As soon as the drafter predicts future tokens, the first mannequin evaluates them utilizing optimized kernels that maximize parallelization throughout verification. This streamlined structure accelerates multi-token throughput with out shedding reasoning high quality.

Enabling MTP within the LiteRT-LM pipeline requires solely two strains of configuration, immediately unlocking as much as 2.2x decoding speedup for low-latency purposes. Numbers reported are collected on Samsung S26 Extremely utilizing the GPU backend.
Session administration for pace and continuity
Superior session administration in LiteRT-LM basically transforms how cell purposes deal with long-context interactions. By supporting native session save and restore capabilities, the engine permits giant KV cache states—representing longer context histories—to be serialized and safely preserved throughout classes. This structure ensures seamless person continuity, permitting conversations or workflows to be resumed seamlessly. Past user-experience advantages, this mechanism supplies higher backend effectivity: preserving context states reduces the necessity for redundant computations and bypasses heavy prefill phases on returning classes. This effectivity powers dynamic options just like the prolonged Agent Expertise within the Google AI Edge Gallery app, driving down general compute prices whereas delivering an extremely quick, end-to-end on-device expertise.
Environment friendly reminiscence utilization
To make sure seamless on-device deployment of Gemma 4’s native imaginative and prescient and audio capabilities, LiteRT-LM employs superior reminiscence footprint optimizations that maximize effectivity inside strict {hardware} constraints. The runtime strategically reduces overhead by holding per-layer embeddings (PLEs) out of reminiscence and by dynamically loading picture and audio encoders solely when a particular job requires them, guaranteeing that text-only workloads stay exceptionally light-weight. LiteRT-LM additionally extremely optimizes general reminiscence consumption for CPU execution, permitting builders to attain strong efficiency whereas sustaining a minimal system footprint—remember to try the official mannequin playing cards (E2B, E4B) for particular reminiscence benchmarks.
The results of these mixed strategies is a lean runtime footprint — as an example, LiteRT-LM efficiently runs the ~2.58GB Gemma 4 E2B mannequin with a bodily reminiscence footprint of simply 607MB on Apple cell CPUs using XNNPACK’s weight caching mechanism. This discount in energetic reminiscence overhead ensures strong, enterprise-grade AI efficiency with out compromising your app’s general stability.
Orchestrating agentic workflows: considering, formatting, and performing
To make sure the mannequin executes extremely complicated, multi-step duties earlier than triggering any exterior actions, LiteRT-LM natively helps Pondering Mode (out there within the Gemma 4 mannequin household). By dedicating a scratchpad for step-by-step reasoning earlier than the mannequin commits to an motion, LiteRT-LM can considerably enhance the output high quality. Builders can select to stream this uncooked reasoning course of on to the UI or strip it to save lots of crucial KV cache house in multi-turn cell classes.
As soon as the mannequin has completed its inner reasoning, holding its output structured is crucial. Coupled with strong constrained decoding (CD), builders can implement strict JSON schemas or particular output grammar on the ultimate generated software payload, utterly eliminating parser breaking.

High quality enchancment from considering + constrained decoding assist, on Samsung S25 Extremely CPU.
With deep considering and strict boundaries established, the mannequin is able to act. Transferring past uncooked technology, LiteRT-LM helps the native function-calling capabilities launched in FunctionGemma and perfected in Gemma 4. The runtime seamlessly pauses execution, returns structured tool-call requests to your software layer, and resumes upon receiving the software’s output.
Increasing the mixing floor
LiteRT-LM was constructed from the bottom as much as be cross-platform, and we at the moment are increasing past Android assist (Kotlin/C++) with new interfaces for Apple ecosystems (Swift API) and the open net (JavaScript API) .
Native Growth with Swift
Increasing its state-of-the-art efficiency for Gemma fashions, LiteRT-LM now unlocks native Apple improvement with a completely open-source iOS Swift API.

Efficiency comparability of LiteRT-LM for iOS Swift Vs. MLX, examined on iPhone 17 Professional.
Excessive-Efficiency browser inference with WebGPU
We’re additionally bringing the facility of LiteRT-LM to the browser. These production-proven inference pipelines at the moment are totally accessible on the net (WASM) by way of our JavaScript API. Powered by WebGPU, LiteRT-LM delivers lightning-fast LLM routing and execution client-side, unlocking net purposes which are serverless, safe, and utterly privacy-preserving. Constructing upon the foundational success of the MediaPipe LLM Inference engine’s web solution, this native net assist in LiteRT-LM represents the following evolution in our on-device AI stack.
LiteRT-LM net demo operating on an Apple MacBook Professional M3 36GB with 18 GPU cores.
Our net resolution presents vital efficiency positive aspects over different web-based LLM frameworks.

Efficiency comparability of LiteRT-LM.js Vs. ONNX Runtime Internet, examined in Chrome on an MacBook Professional 2024 (Apple M4 Max) 48GB with 40 GPU cores.
Trying forward
We’re simply scratching the floor of what’s potential while you carry highly effective LLM inference and true agentic abilities to edge gadgets. LiteRT-LM eliminates the friction of managing reminiscence, {hardware} acceleration, and cross-platform idiosyncrasies, letting you construct the following technology of privacy-first, zero-latency purposes.
We wish you to strive it. Obtain the LiteRT-LM CLI for desktop or AI Edge Gallery for cell, or try the code and APIs as we speak, and we’re excited to see what you construct.
Acknowledgements
We might like to increase a particular because of our key contributors for his or her foundational work on this mission: Advait Jain, Alice Zheng, Cormac Brick, Byungchul Kim, Fengwu Yao, Jae Yoo, Jenn Lee, Lu Wang, Marissa Ikonomidis, Matthew Chan, Matthew Soulanille, Matthias Grundmann, Mohammadreza Heydary, Ram Iyengar, Sachin Kotwani, Salil Tambe, Suleman Shahid, Tenghui Zhu, Tyler Mullen, Vinod Mamillapalli, Wai Hon Legislation, Weiyi Wang, Yi-Chun Kuo, Yu-hui Chen.
Discover this announcement and all Google I/O 2026 updates on io.google.