

As we speak, we’re releasing Mistral OCR 4, that includes bounding bins, block classification, and inline confidence scores alongside extracted textual content. The mannequin helps 170 languages throughout 10 language teams, runs in a single container for absolutely self-hosted deployments, and serves as an ingestion element for enterprise search, RAG, and domain-specific retrieval pipelines. OCR 4 is a small, targeted mannequin, and this put up covers what’s new, the way it performs on public and inner benchmarks, the identified limitations of these benchmarks, and steering on when to make use of the mannequin API versus Doc AI.
Highlights
-
Breakthrough efficiency. Unbiased annotators want OCR 4 over each main OCR and document-AI system examined, with win charges averaging 72%, alongside the highest total rating on OlmOCRBench (85.20). See Benchmarks beneath for methodology and identified scoring limitations.
-
Segmentation, not simply textual content. Alongside the extracted textual content, OCR 4 returns bounding bins, typed-block classification (titles, tables, equations, signatures, and extra), and inline confidence scores. Bounding bins, our most-requested functionality, localize textual content for in-context highlighting and dependable knowledge pipelines. On the identical time, block varieties and confidence scores drive source-grounded citations, redactions, and human-in-the-loop verification.
-
Built-in with Mistral Search Toolkit (public preview). OCR 4 is an ingestion element of Search Toolkit, Mistral’s open-source, composable search framework, introduced on the AI Now Summit. Its structured output provides citation-ready inputs to the toolkit’s ingestion, retrieval, and analysis workflow for RAG and enterprise search.
-
Multilingual protection. Assist for 170 languages throughout 10 language teams, with measurable good points on uncommon and low-resource languages the place a number of competing techniques degrade.
-
Run by yourself infrastructure. OCR 4 is compact sufficient to deploy on a single container, retaining doc knowledge in your surroundings for residency, sovereignty, and compliance, whereas supporting cost-efficient, high-throughput batch processing. Self-managed deployment is offered to enterprise clients.
Overview
Mistral OCR 4 extracts and constructions content material from a variety of paperwork. The place earlier generations targeted on changing a web page into clear textual content and tables, OCR 4 returns a structured illustration of the doc. Every block is localized with a bounding field, categorised by sort, and inline confidence scores are generated per-page and per-word. Downstream techniques, subsequently, have entry not solely to what the doc says but in addition to the place every component sits, what function it performs, and how assured the mannequin is in every area.
This construction helps a number of downstream workloads:
-
Semantic chunking for RAG: clear, categorised blocks turn out to be higher retrieval items.
-
Structural primitives for brokers: brokers transfer from studying paperwork to appearing on them (type filling, bill processing, compliance checks).
-
Structured content material for connectors: constant, typed output for ingestion and indexing pipelines.
OCR 4 accepts widespread enterprise codecs, together with PDF, DOC, PPT, and OpenDocument, and helps 170 languages throughout 10 language teams, together with uncommon and low-resource languages that many techniques deal with poorly. As a compact mannequin deployable in a single container, it’s suited to each cost-sensitive and high-volume deployments. It could actually run absolutely self-hosted, permitting organizations with data-sovereignty necessities to maintain doc knowledge inside their very own infrastructure.
Builders combine the mannequin by way of API, and groups can use Document AI in Mistral Studio for an application-level, no-code path to the identical engine. Mistral OCR 4 via the API is priced at $4 per 1,000 pages, with a 50% Batch-API low cost, decreasing the associated fee to $2 per 1,000 pages. Doc AI is priced at $5 per 1,000 pages.
Benchmarks
“We benchmarked Mistral OCR 4 towards the main agentic doc parsers throughout a chart and determine dense monetary QA dataset and reached equal accuracy at roughly 8x decrease price and 17x decrease latency. For manufacturing use instances at scale, that delta compounds quick.”
– Aidan Donohue, AI Engineer, Rogo
To judge OCR 4, we in contrast it towards main AI-native OCR fashions, frontier general-purpose fashions, enterprise doc providers, and our personal Mistral OCR 3.
Human Choice Evaluations
Automated benchmarks carry the scoring artifacts described above, so we complemented them with a head-to-head human analysis on paperwork chosen to replicate actual utilization. We assembled 600+ paperwork throughout 12+ languages, sourced from third-party distributors to characterize actual trade use instances, and requested impartial annotators to blindly rank every competitor’s output towards OCR 4’s, doc by doc.
Annotators most popular OCR 4 within the majority of paperwork throughout all techniques examined. As a result of these are human judgments on practical paperwork fairly than string comparisons towards fastened references, they sidestep a lot of the annotation and formatting noise that impacts automated scores.
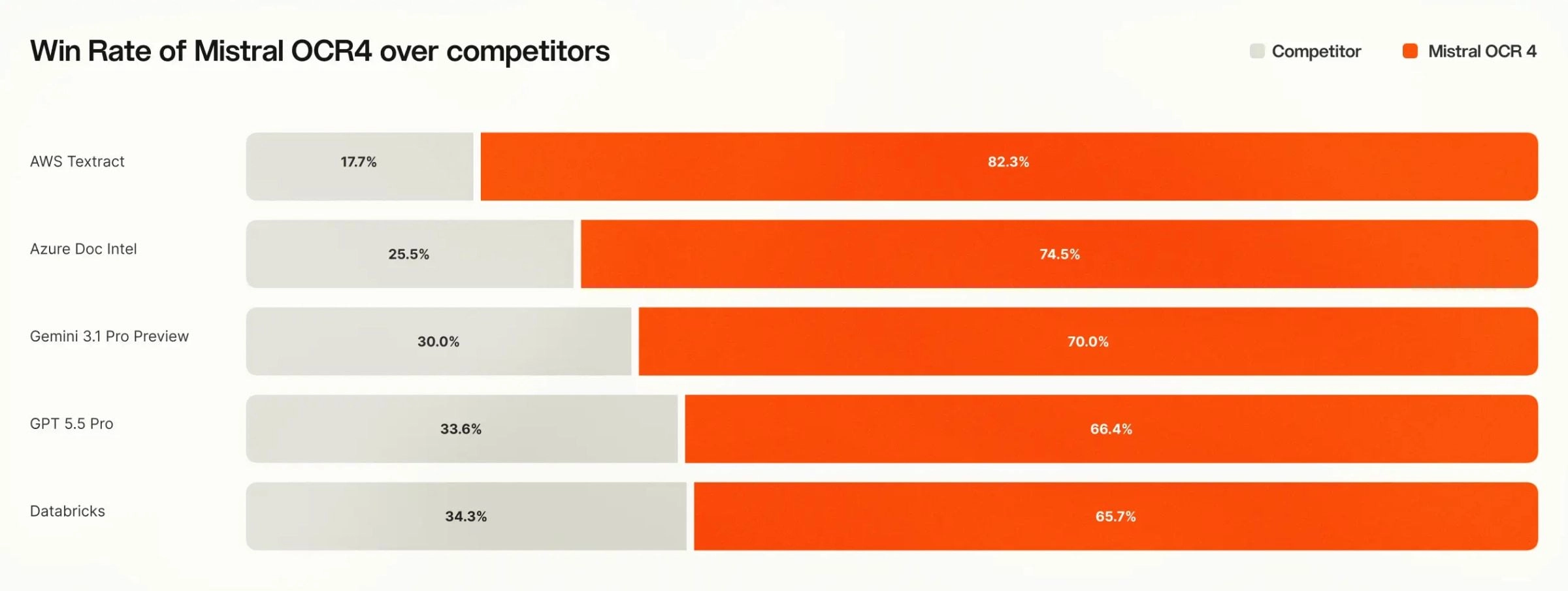
General Efficiency
“Mistral OCR is roughly 4x sooner per web page than our incumbent supplier, a powerful outcome for the high-volume docketing workflows the place pace is essential to managing our clients’ IP timelines.”
– Ivan Mihailov, AI engineer, Anaqua
Along with putting first in our human preferences, OCR 4 achieves the highest total rating amongst the fashions we examined on the general public OlmOCRBench (85.20) and leads our inner Crawl Multilingual analysis (.98), forward of each AI-native and enterprise options.
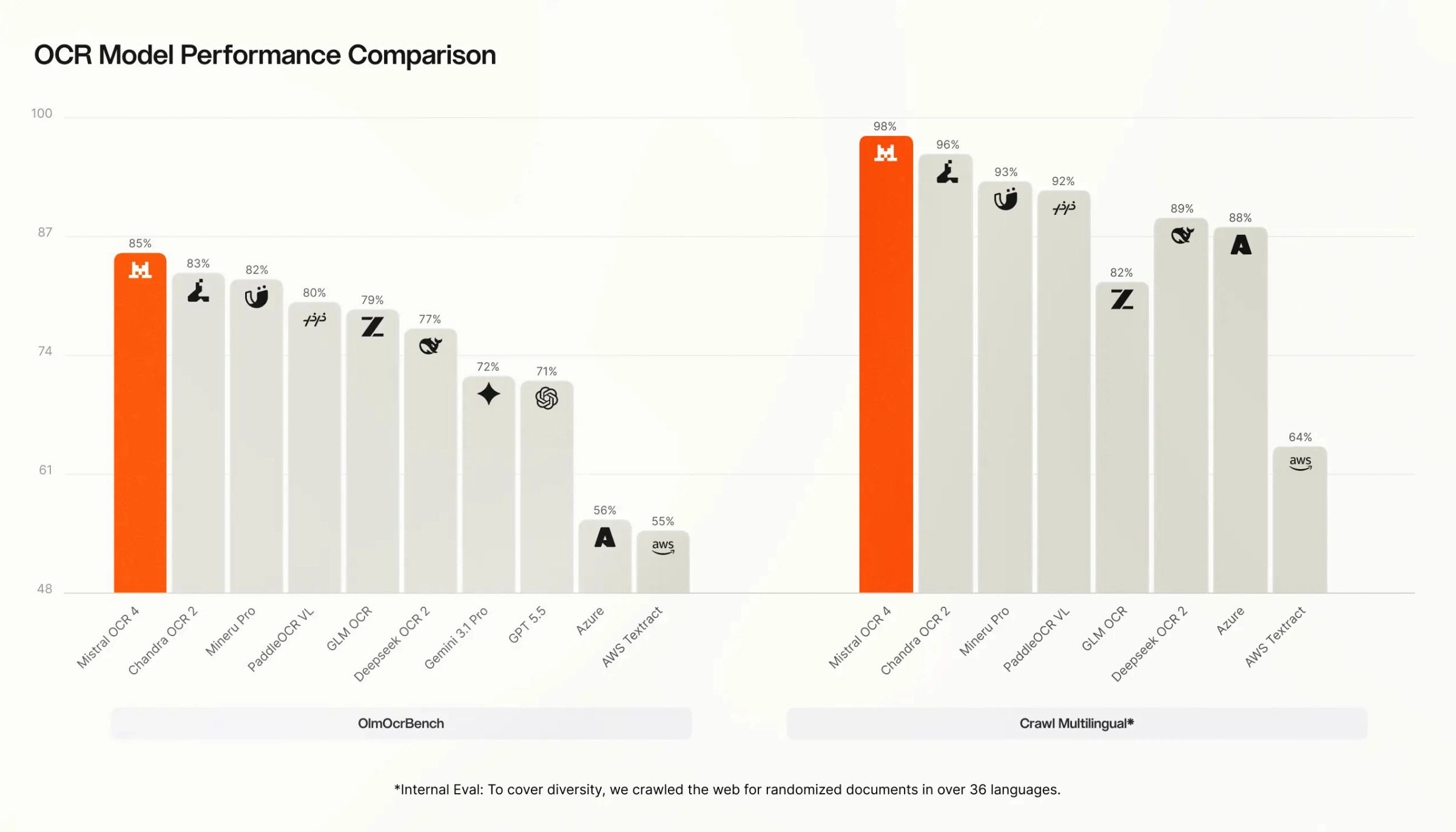
On OmniDocBench, OCR 4 achieves a rating of 93.07. We report this determine with a caveat: each OlmOCRBench and OmniDocBench have identified limitations in how they rating sure outputs, and a single mixture quantity can each understate and overstate real-world efficiency.
Once we audited the mismatches behind our scores, most weren’t mannequin errors however artifacts of how the benchmarks examine output. The recurring classes:
-
Floor-truth errors. Some reference annotations are themselves incorrect: lacking or additional textual content, transcriptions of redacted areas, or typos (for instance, a cited writer’s title misspelled within the reference however learn accurately by the mannequin from the web page). The output matches the supply doc, but it’s nonetheless marked improper.
-
Equal math notation. Totally different LaTeX that renders identically is counted as a mismatch, The rendered equation is appropriate; the string comparability is just not.
-
Equation segmentation. Whether or not an expression is emitted as a single equation or cut up into a number of inline fragments impacts the match, even when the rendered content material is an identical, as a result of the matcher can not align the items.
-
Multi-column studying order. Phrases cut up throughout a column boundary (for instance, “certifi-cates”) and column-ordering assumptions trigger appropriate extractions to be scored as reading-order failures.
-
Block-type attribution. The benchmark doesn’t count on headers/footers within the output. To resolve this we strip headers footers from our output earlier than scoring. However the take a look at then checks for a string that additionally occurs to be the title of the web page which ought to truly be current and flags it incorrectly.
These artifacts focus in mathematical, scientific, and multi-column paperwork, and so they extra usually penalize appropriate output than reward incorrect output. We subsequently deal with the combination rating as directional fairly than definitive.
We report these numbers to point the place OCR 4 stands, and suggest evaluating by yourself paperwork.
Efficiency Particulars
Crawl Multilingual breakdown. On our inner multilingual analysis, OCR 4 leads throughout all eight language teams — English, Western Europe, Jap Europe, Center Jap, Chinese language, East Asian, Southeast Asian, and uncommon languages (Hindi, Japanese, Georgian, Bengali, Armenian, Hebrew, Greek, Gujarati, Tamil, Malayalam, Kannada, Telugu). The hole is widest for uncommon and low-resource languages, the place many competing techniques degrade sharply, whereas OCR 4 maintains excessive accuracy.
Really helpful use instances
OCR 4 helps each high-volume pipelines and interactive doc workflows, together with:
-
Doc parsing and extraction: complicated, multilingual paperwork.
-
Retrieval-Augmented Technology (RAG): structured, categorised, citation-ready content material for semantic chunking and source-grounded solutions. With Search Toolkit, OCR 4 output may be fed straight into retrieval pipelines.
-
Agentic workflows: offering brokers with the structural primitives to finish duties akin to type filling, bill processing, and compliance checks, particularly in authorized, monetary providers, and healthcare.
-
Structured knowledge pipelines utilizing confidence scores to allow environment friendly use of human verifiers: type/bill extraction, redactions, and compliance-driven processes.
-
Enterprise search and information bases: OCR as a data-source element for customized ingestion and entity extraction.
Early customers are making use of OCR 4 to show invoices into structured fields, digitize firm archives, extract clear textual content from technical and scientific experiences, and energy enterprise search.
A notice on out-of-scope use. OCR 4 is a document-understanding mannequin, not a decision-maker. It’s not meant for medical analysis, authorized recommendation or judgment, high-stakes monetary selections, safety-critical techniques, real-time/latency-sensitive processing, or non-document inputs (uncooked audio, video, and so forth.).
OCR 4 API: Understanding Your Choices
Mistral’s OCR 4 is offered via a single API endpoint. Each request runs the identical underlying OCR mannequin and all the time returns extracted content material, bounding bins, block varieties, confidence scores, and markdown-structured textual content. What varies is how a lot you layer on high.
Use OCR 4 in pure extraction mode whenever you wish to:
-
Embed quick, correct doc extraction straight into your utility, agent, or knowledge pipeline.
-
Work straight with the uncooked response, bounding bins, block varieties, and confidence scores to drive customized downstream logic.
-
Run high-volume or batch ingestion with full management over throughput and price by way of the Batch API.
-
Self-host for strict data-privacy, sovereignty, or compliance necessities.
Activate Doc AI capabilities (identical endpoint, further parameters) whenever you wish to:
-
Return structured JSON in a schema you outline — move a JSON schema alongside your doc, and the OCR output is fed to
mistral-small-2603to generate content material formed to your spec. -
Annotate detected pictures with structured JSON by passing a picture annotation schema, triggering a further vision-language mannequin name per picture.
-
Use a customized immediate alongside a JSON schema to information how the extracted content material of the complete doc is interpreted or summarized.
-
Allow enterprise customers, options groups, or pilots to supply structured outcomes with out writing downstream parsing logic.
The sensible choice rule: should you want uncooked extracted content material, use OCR 4 as-is. In the event you want the output reshaped right into a structured format, annotated with domain-specific fields, or processed with a customized instruction, add the Doc AI parameters to the identical name. You all the time get the OCR outcome regardless; Doc AI merely provides structured layers on high of it.
Now accessible
“The provision of Mistral Doc AI with OCR 4 in Microsoft Foundry marks an essential milestone in our partnership. Collectively, we’re enabling clients to convey superior, structured doc understanding straight into their AI workflows, combining Mistral’s innovation with Microsoft’s enterprise platform to ship scalable, trusted options for real-world enterprise wants.”
-Kimmi Grewal, VP, AI Ecosystem Partnerships, Microsoft
Each Mistral OCRv4 and Doc AI (powered by OCRv4) can be found via API via Mistral Studio, Amazon SageMaker, Microsoft Foundry, and coming quickly Snowflake Parse Doc. For organizations with stringent data-privacy necessities, OCR 4 additionally gives a self-hosting possibility so delicate data stays inside your individual infrastructure. To discover self-deployment, let us know.
Get began
We provide a couple of methods to get began and be taught extra rapidly.