

I wished to present an replace on GitHub’s availability in gentle of two recent incidents. Each of these incidents usually are not acceptable, and we’re sorry for the impression that they had on you. I wished to share some particulars on them, in addition to clarify what we’ve accomplished and what we’re doing to enhance our reliability.
We began executing our plan to extend GitHub’s capability by 10X in October 2025 with a purpose of considerably bettering reliability and failover. By February 2026, it was clear that we wanted to design for a future that requires 30X in the present day’s scale.
The principle driver is a fast change in how software program is being constructed. Because the second half of December 2025, agentic growth workflows have accelerated sharply. By practically each measure, the route is already clear: repository creation, pull request exercise, API utilization, automation, and large-repository workloads are all rising rapidly.
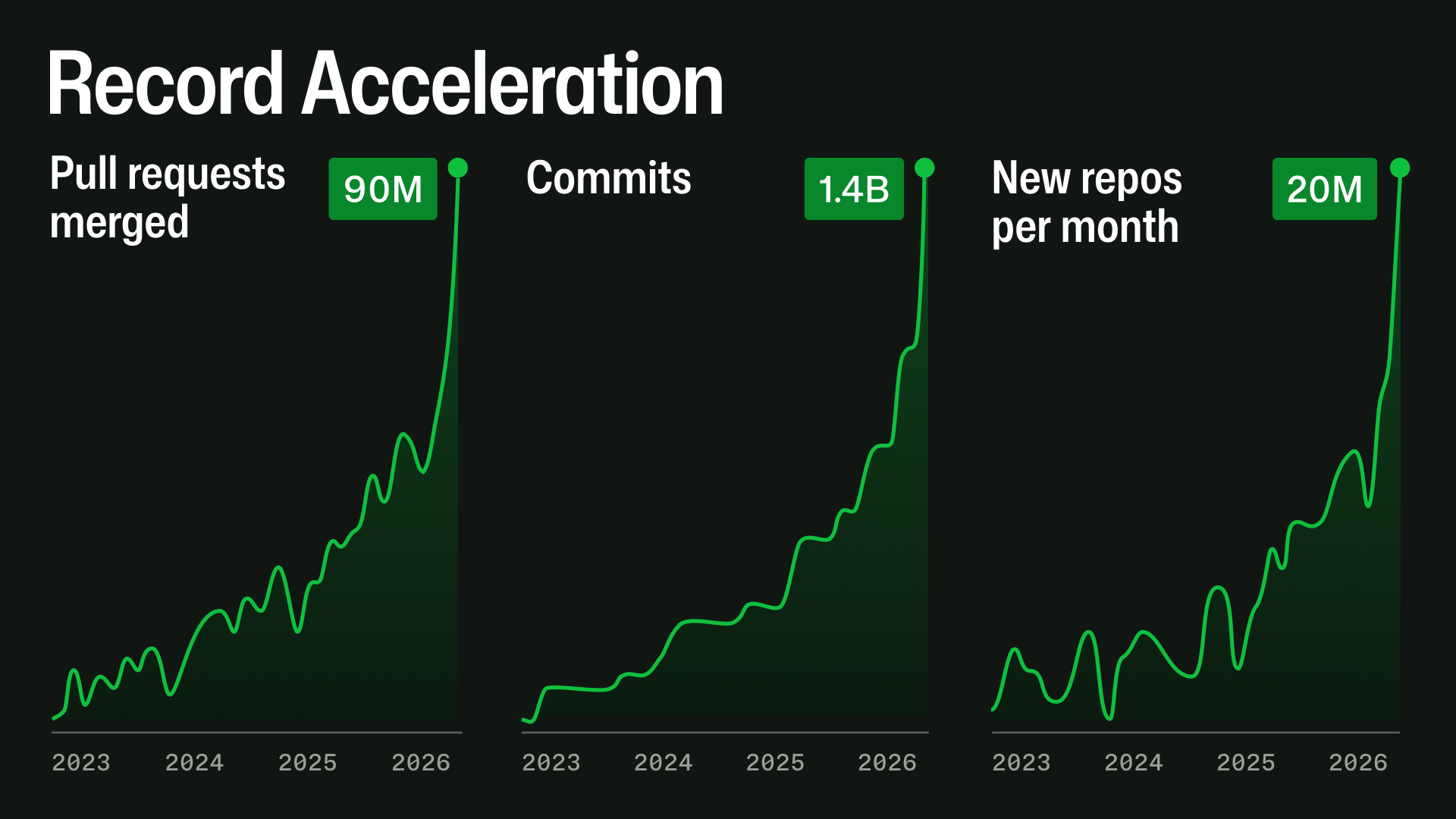
This exponential development doesn’t stress one system at a time. A pull request can contact Git storage, mergeability checks, department safety, GitHub Actions, search, notifications, permissions, webhooks, APIs, background jobs, caches, and databases. At excessive scale, small inefficiencies compound: queues deepen, cache misses change into database load, indexes fall behind, retries amplify site visitors, and one gradual dependency can have an effect on a number of product experiences.
Our priorities are clear: availability first, then capability, then new options. We’re lowering pointless work, bettering caching, isolating important providers, eradicating single factors of failure, and shifting performance-sensitive paths into methods designed for these workloads. That is distributed methods work: lowering hidden coupling, limiting blast radius, and making GitHub degrade gracefully when one subsystem is below strain. We’re making progress rapidly, however these incidents are examples of the place there’s nonetheless work to do.
What we’re doing
Quick time period, we needed to resolve a wide range of bottlenecks that appeared quicker than anticipated from shifting webhooks to a distinct backend (out of MySQL), redesigning person session cache to redoing authentication and authorization flows to considerably scale back database load. We additionally leveraged our migration to Azure to face up much more compute.
Subsequent we centered on isolating important providers like git and GitHub Actions from different workloads and minimizing the blast radius by minimizing single factors of failure. This work began with cautious evaluation of dependencies and completely different tiers of site visitors to know what must be pulled aside and the way we will decrease impression on official site visitors from varied assaults. Then we addressed these so as of danger. Equally, we accelerated elements of migrating efficiency or scale delicate code out of Ruby monolith into Go.
Whereas we have been already in progress of migrating out of our smaller customized information facilities into public cloud, we began engaged on path to multi cloud. This longer-term measure is important to realize the extent of resilience, low latency, and suppleness that might be wanted sooner or later.
The variety of repositories on GitHub is rising quicker than ever, however a a lot more durable scaling problem is the rise of huge monorepos. For the final three months, we’ve been investing closely in response to this pattern each inside git system and within the pull request expertise.
We could have a separate weblog submit quickly describing in depth work we’ve accomplished and the brand new upcoming API design for larger effectivity and scale. As a part of this work, we have now invested in optimizing merge queue operations, since that’s key for repos which have many 1000’s of pull requests a day.
Latest incidents
The 2 current incidents have been completely different in trigger and impression, however each replicate why we’re rising our concentrate on availability, isolation, and blast-radius discount.
April 23 merge queue incident
On April 23, pull requests skilled a regression affecting merge queue operations.
Pull requests merged by way of merge queue utilizing the squash merge technique produced incorrect merge commits when a merge group contained multiple pull request. In affected instances, adjustments from beforehand merged pull requests and prior commits have been inadvertently reverted by subsequent merges.
Through the impression window, 230 repositories and a pair of,092 pull requests have been affected. We initially shared barely increased numbers as a result of our first evaluation was deliberately conservative. The problem didn’t have an effect on pull requests merged outdoors merge queue, nor did it have an effect on merge queue teams utilizing merge or rebase strategies.
There was no information loss: all commits remained saved in Git. Nonetheless, the state of affected default branches was incorrect, and we couldn’t safely restore each repository robotically. Extra particulars can be found within the incident root trigger evaluation.
This incident uncovered a number of course of failures, and we’re altering these processes to stop this class of situation from recurring.
April 27 search-related incident
On April 27, an incident affected our Elasticsearch subsystem, which powers a number of search-backed experiences throughout GitHub, together with elements of pull requests, points, and initiatives.
We’re nonetheless finishing the foundation trigger evaluation and can publish it shortly. What we all know now’s that the cluster grew to become overloaded (probably resulting from a botnet assault) and stopped returning search outcomes. There was no information loss, and Git operations and APIs weren’t impacted. Nonetheless, elements of the UI that trusted search confirmed no outcomes, which precipitated a big disruption.
This is likely one of the methods we had not but absolutely remoted to get rid of as a single level of failure, as a result of different areas had been increased in our risk-prioritized reliability work. That impression is unacceptable, and we’re utilizing the identical dependency and blast-radius evaluation described above to scale back the probability and impression of such a failure sooner or later.
Rising transparency
We’ve got additionally heard clear suggestions that prospects want larger transparency throughout incidents.
We not too long ago up to date the GitHub status page to incorporate availability numbers. We’ve got additionally dedicated to statusing incidents each giant and small, so that you shouldn’t have to guess whether or not a problem is in your aspect or ours.
We’re persevering with to enhance how we categorize incidents in order that the dimensions and scope are simpler to know. We’re additionally engaged on higher methods for patrons to report incidents and share alerts with us throughout disruptions.
Our dedication
GitHub’s position has all the time been to assist builders on an open and extensible platform.
The crew at GitHub is extremely obsessed with our work. We hear the ache you’re experiencing. We learn each e-mail, social submit, assist ticket, and we take all of it to coronary heart. We’re sorry.
We’re dedicated to bettering availability, rising resilience, scaling for the way forward for software program growth, and speaking extra transparently alongside the way in which.
Written by
