
Anthropic has launched auto mode in Claude Code, enabling multi-step software program improvement duties with decreased handbook intervention. Builders outline goals whereas the system handles code technology, execution, device use, and iterative refinement, with human approval required at chosen checkpoints for delicate operations.
Beforehand, Claude Code relied on a permission-based mannequin the place customers needed to approve most actions, corresponding to operating instructions and modifying information. Whereas this offered robust security and management, it launched friction in longer periods as a result of repeated confirmations, resulting in approval fatigue the place customers spent extra time managing prompts than specializing in improvement work.
Sid Chaudhary, Head of Product at Intempt, noted,
Now you can run Claude and truly stroll away. Espresso break. Precise stroll. You do not babysit it.
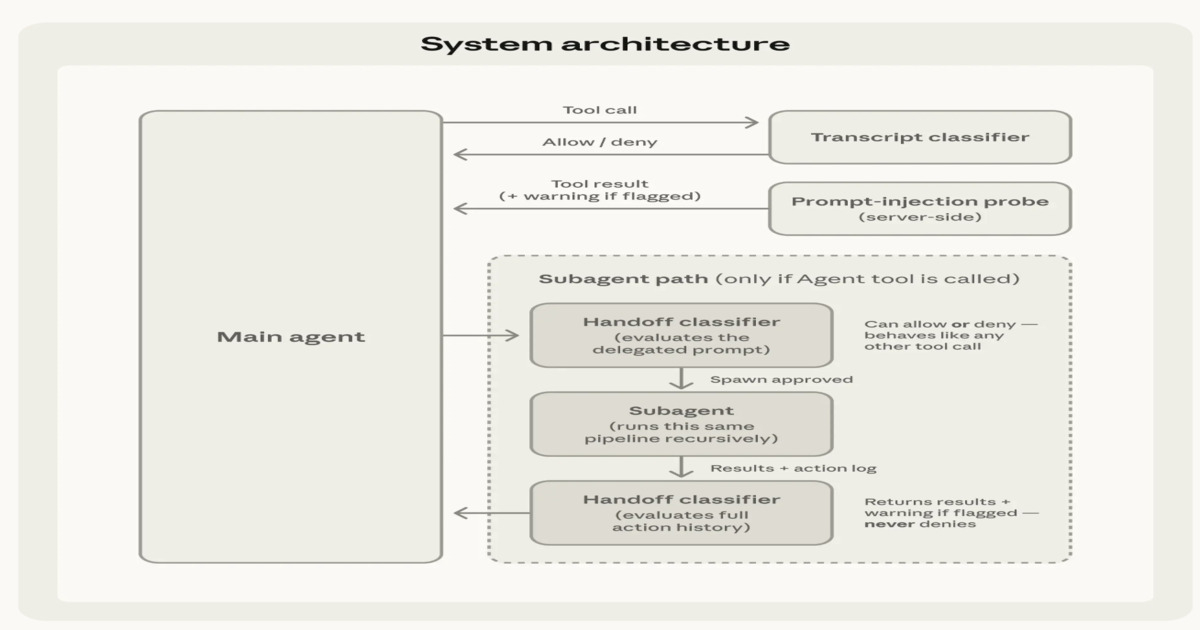
Auto mode introduces a layered security and execution structure that governs each how inputs are processed and the way actions are executed. On the enter layer, device outputs corresponding to file reads, shell outcomes, and net responses are inspected earlier than being integrated into the system context. When content material seems malicious or makes an attempt to change directions, warnings are injected to make sure it’s handled as untrusted and doesn’t override person intent.

Excessive-level structure of Claude Code Auto Mode (Supply: Anthropic Blog Post)
On the execution layer, every proposed motion is evaluated earlier than being run, functioning as an automatic approval mechanism that filters secure operations whereas routing ambiguous circumstances for added checks. This reduces repetitive person intervention whereas preserving safeguards for high-impact or doubtlessly unsafe operations.
Ankit Kalluraya, a Check Engineer, described the interface habits in auto mode,
In auto mode, the spinner now turns purple when a permission verify is triggered, providing you with a transparent visible sign that Claude is pausing for approval.
The system makes use of a two-stage classification strategy to stability effectivity and protection. A quick preliminary filter processes most device calls, permitting secure actions to proceed with minimal overhead. Solely unsure or doubtlessly dangerous operations are escalated to deeper evaluation. This improves recall for edge circumstances whereas controlling latency and compute price, whereas sustaining constant enforcement of security and intent alignment.

Two-stage classification pipeline balancing effectivity, latency, and security protection (Supply: Anthropic Blog Post)
Mykola Kondratiuk, Director at Playtika, noted,
With Auto Mode on, the AI is now the approver, not simply the actor. Most governance docs nonetheless identify a human there and have not been up to date.
Mayank Agrawal, Lead Engineer at Zethra OS, said in a post,
That is the place resilience turns right into a safety downside.
Auto mode additionally extends security checks to subagent workflows. Throughout delegation, outbound checks validate whether or not the assigned job aligns with person intent earlier than execution begins. On completion, a return verify evaluates the subagent’s full execution historical past to detect potential immediate injection or manipulation throughout runtime. If dangers are recognized, warnings are added earlier than outcomes are returned to the orchestrating agent.
Anthropic notes that it’s going to proceed enhancing security and value tradeoffs by means of expanded analysis units and iterative refinement, aiming to catch sufficient high-risk actions to make autonomous operation safer than no guardrails whereas encouraging customers to stay conscious of residual danger and report points.