

Secret scanning performs a vital function in defending builders and organizations. It helps catch uncovered credentials early and prevents small errors from turning into actual incidents.
At GitHub’s scale, even small inefficiencies create actual friction. Too many false positives make alerts more durable to belief.
When alerts really feel noisy, builders spend extra time triaging and fewer time fixing actual points. Over time, this slows down remediation and reduces confidence within the system.
To deal with this problem, GitHub collaborated with Microsoft Safety & AI’s Brokers Offense crew to deliver extra contextual reasoning into GitHub’s secret scanning verification. The collaboration utilized the verification method from Agentic Secret Finder, a broader detection and verification system developed to know potential secrets and techniques in context, not simply whether or not they match a secret-like sample. This helped GitHub discover methods to cut back low-value alerts whereas preserving the protection you count on from secret scanning.
Secret scanning at GitHub at present
GitHub secret scanning combines pattern-based detection with AI-based detection to establish potential secrets and techniques. Sample-based detection catches identified secret codecs, reminiscent of companion patterns for tokens and API keys. AI-powered generic secret detection expands protection to unstructured secrets and techniques like passwords that don’t match a identified supplier sample.
GitHub already has industry-leading precision for provider-pattern secret detection at large scale, processing billions of pushes and defending tens of hundreds of thousands of builders throughout hundreds of thousands of repositories.
As GitHub expanded into AI-powered secret detection, the subsequent problem was bringing the precision of AI-detected secrets and techniques nearer to the identical excessive normal as provider-pattern detections. This collaboration targeted on combining GitHub’s large-scale detection pipeline with LLM-based contextual verification to enhance alert high quality and developer belief.
Our method: Make secret scanning alerts reliable
Secret scanning is most helpful when you may rapidly inform which alerts want motion.
GitHub already has safeguards to cut back noise, however some secret-like values want extra context to find out whether or not they signify an actual publicity. To make these alerts simpler to belief, we added extra reasoning to the verification step.
By taking a look at how a detected worth seems in code, the system can higher separate actual exposures from values that solely look delicate. This helps you spend much less time investigating low-value alerts and extra time fixing the problems that matter.
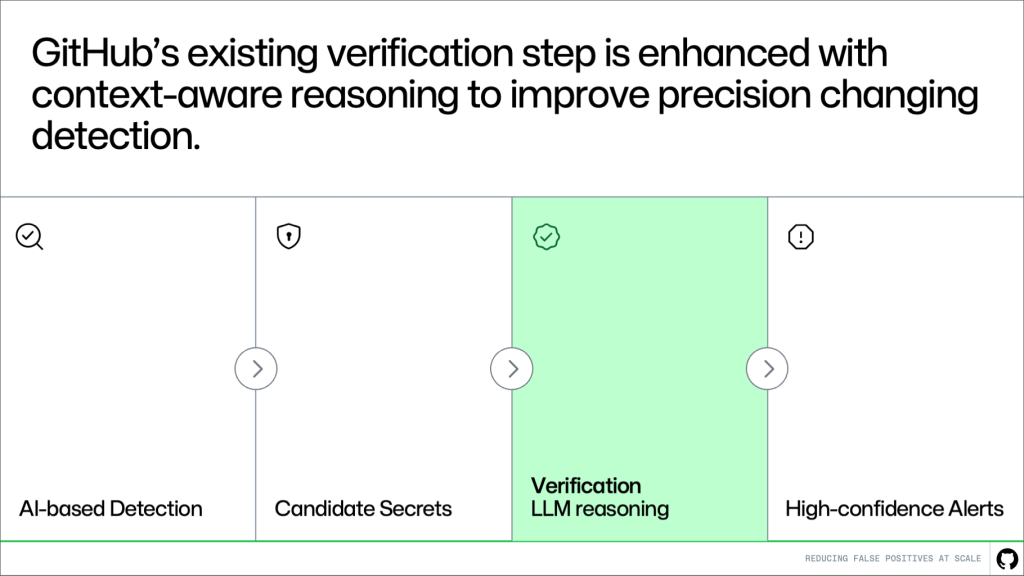
The place this suits within the pipeline
This method builds immediately on the present system. Detection continues to generate candidates, and the verification step evaluates them. Extra context-awareness makes this technique higher at distinguishing actual secrets and techniques from noise.
The result’s larger precision with out altering upstream detection logic or lowering protection.
The way it works
A key problem in verification is deciding what context to offer.
A small snippet of code is commonly not sufficient to find out whether or not one thing is an actual secret. On the identical time, passing whole information or repositories introduces an excessive amount of noise and will increase value and latency.
As a substitute of giving extra context, we’re giving higher context.
Slightly than ship giant quantities of code, we extract a small set of high-signal info that helps clarify how the worth is used. For instance, we search for instances the place a price is assigned to a variable and later handed into an API request, authentication header, database consumer, or cloud SDK name. Sample matching can inform us {that a} worth seems to be like a secret, however it could possibly’t inform us whether or not the worth is definitely getting used as one. The encompassing utilization context helps the mannequin distinguish actual exposures from false alarms, reminiscent of random UUIDs or opaque strings, with out reviewing the complete file or repository.

Centered context, no more information
It’s pure to imagine that enhancing accuracy requires analyzing extra of the codebase. However the reverse is true.
Most false positives could be resolved with targeted, file-level context. What issues isn’t how a lot code the mannequin sees, however whether or not it has the proper alerts.
In lots of instances, you may decide whether or not a price is an actual secret by taking a look at how it’s used inside a single file. Values that resemble placeholders, check information, or unused configuration can typically be filtered out with out deeper evaluation.
This retains the system each efficient and sensible: excessive accuracy, low latency, and the power to scale throughout giant codebases.
Outcomes: lowering false positives in observe
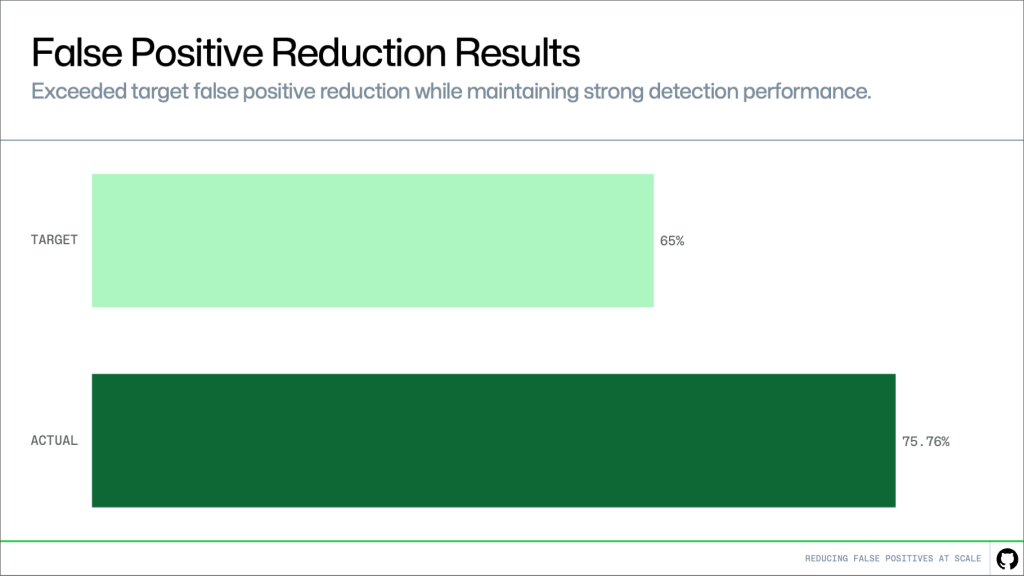
We evaluated this method on a whole bunch of customer-confirmed false constructive alerts.
Our goal was a 65% discount. The consequence was 75.76%, exceeding that aim whereas sustaining robust detection efficiency.
In observe, this implies considerably much less noise and the next proportion of alerts that require motion.
This enchancment exhibits up immediately within the developer expertise. With fewer irrelevant alerts, it turns into simpler to belief what you see. Much less time is spent triaging noise, and actual points could be prioritized and stuck quicker.
What’s subsequent
We’re persevering with to guage this method on bigger datasets and reside visitors, whereas enhancing how context is extracted and used for verification.
Lowering false positives has been a constant want at scale. This work focuses on enhancing sign high quality the place it issues most, making alerts simpler to belief and act on.
The aim is easy: fewer distractions, clearer alerts, and quicker motion on actual dangers.
Get began by running the risk assessment for your organization at present, or learn more about secret scanning.
Written by
