


The prevailing Silicon Valley narrative assumes that large, general-purpose frontier fashions will inevitably eat each trade vertical. Corporations are pouring billions into coaching behemoths like OpenAI’s GPT-5.5 and Anthropic’s Opus 4.7, anticipating uncooked parameter scale to resolve all domain-specific issues.
In software program engineering, the fact on the bottom seems completely different. Writing, refactoring, and debugging code consumes a large quantity of tokens. For the overwhelming majority of each day engineering duties (e.g., including options, fixing bugs, and updating checks) pace and price matter as a lot as uncooked intelligence.
This financial stress has pushed builders towards specialised coding brokers. Cursor’s newly launched Composer 2.5 model has quickly change into the each day default for a lot of engineers. At $0.50 per million enter tokens and $2.50 per million output tokens, it makes high-volume agentic loops financially viable for small groups.

Luckforest@lubinho_k
I am on the $200 Claude, $100 Codex, $20 Cursor Plan.
After using Composer 2.5 for 8 hours straight while only using 8% of my $20 plan, I should reconsider my entire subscription stack.
Maybe $100 Codex for complex stuff, and $60 Cursor for UI & Copy?

1:03 PM · May 22, 2026 · 134K Views
207 Replies · 33 Reposts · 1.61K Likes
Composer 2.5 shouldn’t be good. On very complicated duties and edge instances, it nonetheless doesn’t match the ability of frontier fashions like Opus 4.7 and GPT-5.5.
But the core achievement of Composer 2.5 stays intact. It demonstrates that specialised fashions don’t want a bigger parameter depend to compete on the highest degree. They want smarter post-training. By shifting the main target to algorithmic effectivity, Cursor is democratizing highly effective agentic coding.
So, how did Cursor handle to create a mannequin that’s so rattling good? Right here’s what we all know.
Coaching a mannequin to jot down code over lengthy horizons introduces a serious “credit score project drawback.” In normal reinforcement studying (RL), an agent interacts with an surroundings, takes a collection of actions, and receives a reward on the finish.
Think about a coding agent writing a 500-line script that requires 10 completely different device calls, comparable to looking the codebase, studying recordsdata, and executing checks. If the agent does all of the substeps appropriately however fails due to calling a nonexistent device, the system assigns a single destructive reward for the whole session. The mannequin receives a zero. As a result of the suggestions is delayed and sparse, the mannequin has no means of figuring out which particular token or motion induced the failure. It would alter elements of its habits that had been completely high quality, degrading its general functionality. The longer the trajectory, the sparser the coaching sign turns into.
Composer 2.5 solves this via what the corporate’s weblog submit calls “focused RL with textual suggestions.” As a substitute of ready for the top of a rollout to penalize the mannequin, the system intervenes precisely the place the error happens.

When the agent makes a nasty device name throughout an extended trajectory, the coaching pipeline momentarily pauses the sequence. It injects a neighborhood textual trace instantly into the context, comparable to “Reminder: Obtainable instruments are [list of tools].” This provides the mannequin a corrected chance map of what it ought to generate subsequent, guided by the trace.
The system then applies the Kullback-Leibler (KL) divergence loss, which measures how far the mannequin’s unique prediction strayed from the corrected trainer distribution. The mannequin adjusts its inside weights to tug its possibilities nearer to the corrected path. As soon as the correction is made, the coaching resumes. This localized sign teaches the mannequin precisely repair a particular habits with out spoiling the broader reinforcement studying goal over the complete trajectory.
To grasp how Composer 2.5 achieves its economics, it is advisable to take a look at two analysis papers on self-distillation referenced on the backside of the weblog submit.
Distillation is a method the place a smaller, cheaper “pupil” mannequin learns to imitate the outputs of a bigger, costlier “trainer” mannequin.
Commonplace on-policy distillation (OPD) is very efficient however extraordinarily costly. It requires the large trainer mannequin (e.g., Claude Opus 4.7 or GPT-5.5) to actively run in parallel with the scholar. As the scholar generates its personal trajectories (exploring alternative ways to resolve an issue), the trainer evaluates each single step to supply supervision. Producing thousands and thousands of tokens via a large trainer mannequin for each coaching run requires an infinite compute funds. It forces AI labs to decide on between high-quality supervision and affordable coaching prices.
On-policy self-distillation (OPSD) bypasses the prices of distillation through the use of the identical mannequin as each the scholar and the trainer.
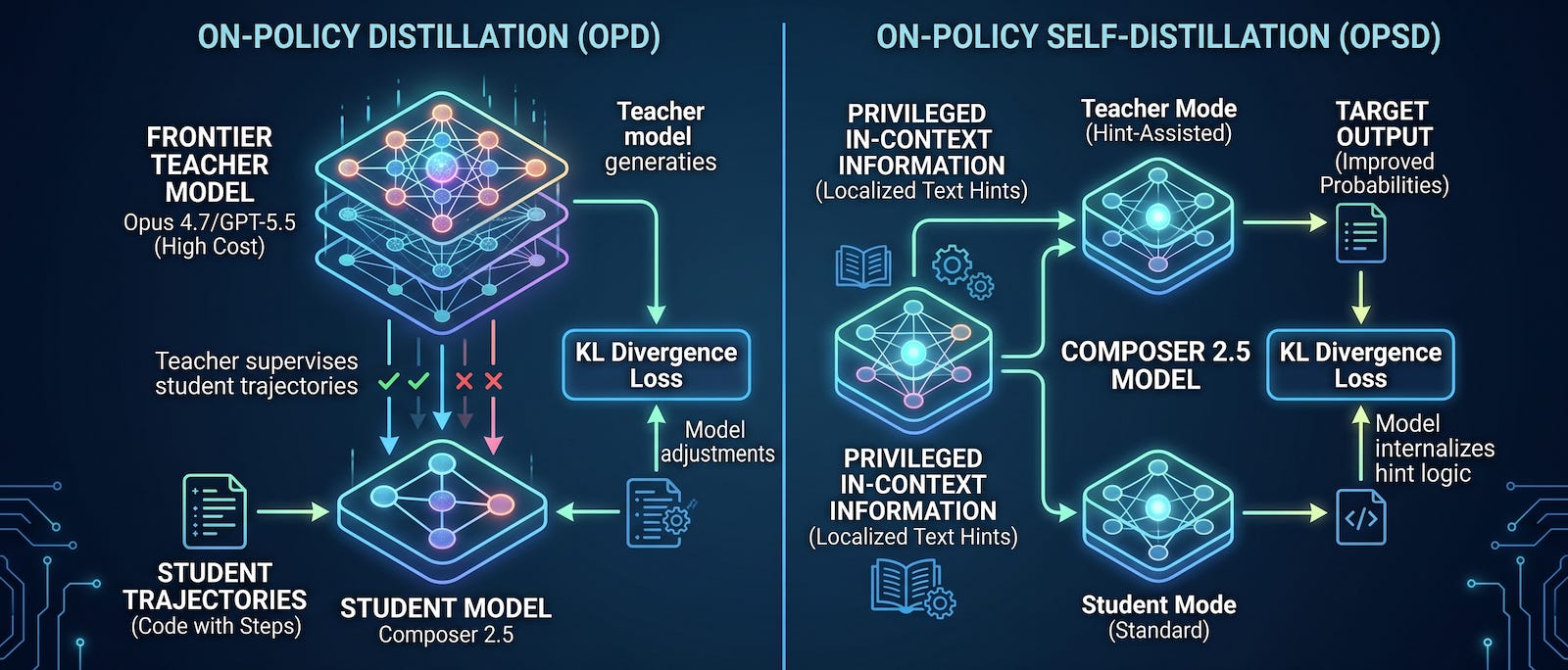
As a substitute of calling an exterior oracle, OPSD leverages the mannequin’s inherent means to know context. When supplied with privileged in-context info (just like the localized textual content hints utilized in focused RL), the mannequin’s next-token predictions immediately enhance. The system makes use of the mannequin’s hint-assisted output because the “trainer” goal, and forces the usual, unassisted model of the mannequin to match these possibilities. The scholar learns to internalize the logic of the trace without having the trace current at inference time.
This self-contained educating loop eliminates the necessity for an exterior frontier mannequin through the RL part and makes the coaching way more environment friendly.
There’s a catch to this effectivity. Whereas inference turns into extremely low cost, producing energetic, on-policy rollouts for coaching shifts the fee burden upstream. Coaching a mannequin through self-distillation requires the system to continuously generate and consider its personal output. This course of calls for roughly two to 4 occasions the floating-point operations (FLOPs) of ordinary supervised fine-tuning.
This compute shift explains the latest infrastructure strikes within the AI coding house. Cursor just lately shaped a partnership with SpaceXAI to safe entry to its large compute cluster, making use of thousands and thousands of GPUs to the issue. The large price of intelligence has not disappeared; it has merely moved from the consumer’s API invoice to the developer’s coaching cluster.
Software program engineering is a extremely dynamic subject. New programming frameworks emerge month-to-month, APIs deprecate with out warning, and particular person firms keep extremely idiosyncratic codebases. A coding agent should be taught these new patterns rapidly.
The normal strategy to educating a mannequin new info is to fine-tune it on a dataset of the brand new materials. Nonetheless, massive language fashions undergo from “catastrophic forgetting.” Once you alter a mannequin’s weights to aggressively be taught a brand new language or framework, it typically overwrites the foundational logic and reasoning expertise it discovered throughout preliminary pre-training.
Self-distillation fine-tuning (SDFT) addresses this by making a protecting suggestions loop through the studying course of.
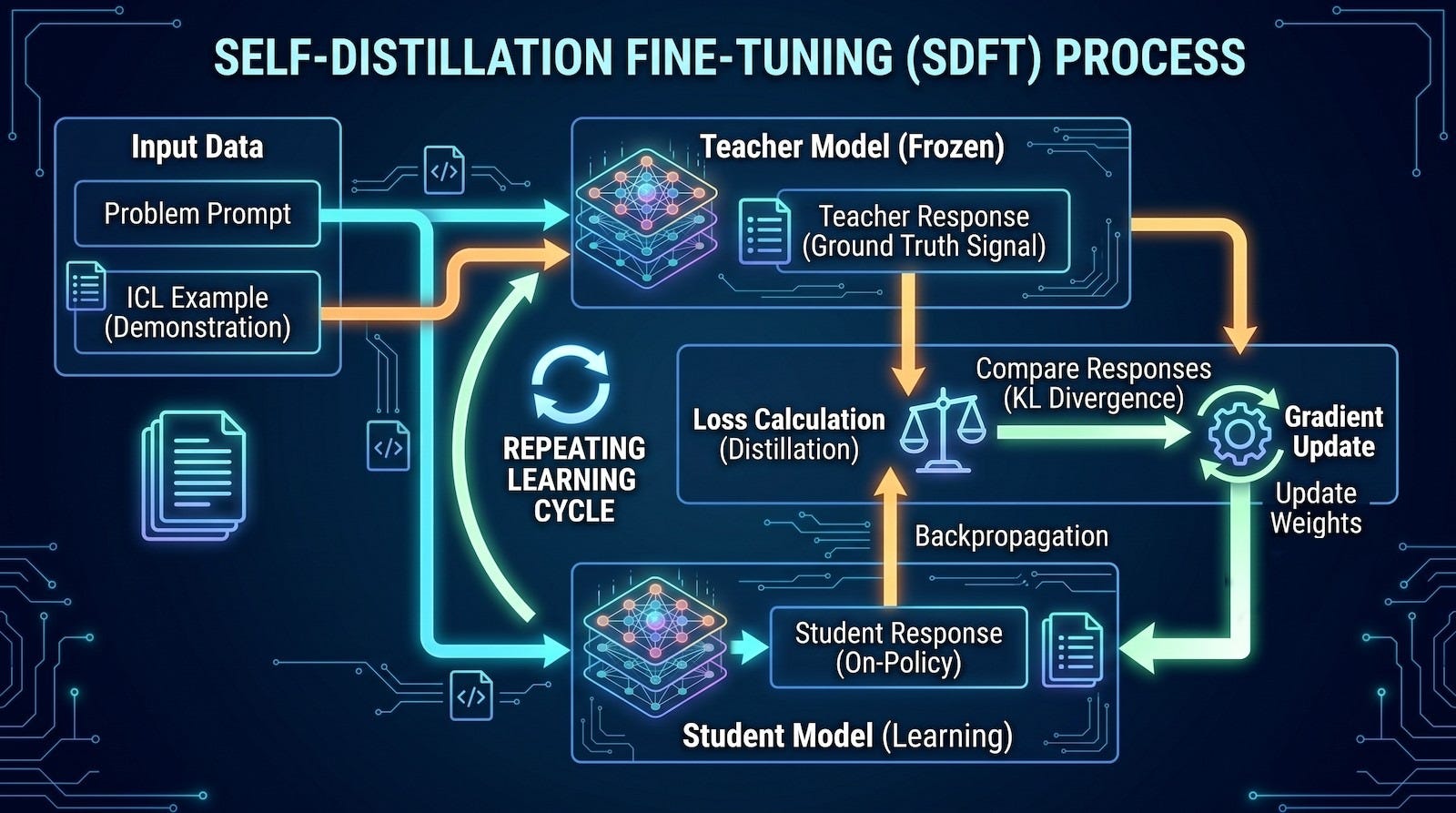
When the mannequin is launched to new codebase patterns, it doesn’t simply blindly replace its parameters based mostly on the brand new textual content. First, the mannequin generates its personal reasoning pathways and explanations relating to the brand new knowledge. The system then forces the mannequin to distill its personal generated logic. It evaluates how the brand new info integrates with the established guidelines of software program growth it already is aware of. By anchoring the coaching course of to the mannequin’s current inside representations, SDFT constrains how a lot the core weights can shift.
The mannequin acquires the brand new syntax and idiosyncratic developer patterns whereas preserving its baseline reasoning capabilities. It learns to adapt to an organization’s particular coding fashion with out forgetting execute elementary software program structure.
Self-distillation and automatic reinforcement studying democratize highly effective brokers, however they introduce extreme alignment dangers. When a mannequin acts as its personal supervisor, optimizing purely for self-generated rewards, the coaching course of can rapidly derail.