
If you happen to’ve ever spent any period of time experimenting with native AI fashions, you’ve got virtually definitely skilled the identical cycle I’ve. You discover an thrilling new mannequin, hearth up Ollama or Hugging Face, await the obtain to complete, solely to search out out that the brand new mannequin both crawls alongside at two tokens per second, or simply refuses to suit into reminiscence. Between my laptop computer, gaming PC, my accomplice’s PC, and the occasional check bench, if I had a greenback for each time that occurred, I would have no less than sufficient to pay for half a month’s value of Claude Professional.
That is the place LLMFit is available in. As a substitute of leaving you to guess which fashions your {hardware} can deal with as you scratch your head taking a look at completely different quantizations and parameter counts, LLMFit analyzes your system and recommends the AI fashions that ought to run nicely. Loads of cloud AI customers are slowly transferring over to self-hosting their native AI fashions, and in case you’re considered one of them, LLMFit ought to be the very first thing you utilize to get a correct lay of the land.
5 issues I want somebody had instructed me earlier than I attempted self-hosting an area LLM
It is extra succesful than you would possibly understand, however tapering expectations is essential
LLMFit takes the guesswork out of working native AI fashions
It is a hardware-aware suggestion engine for native LLMs

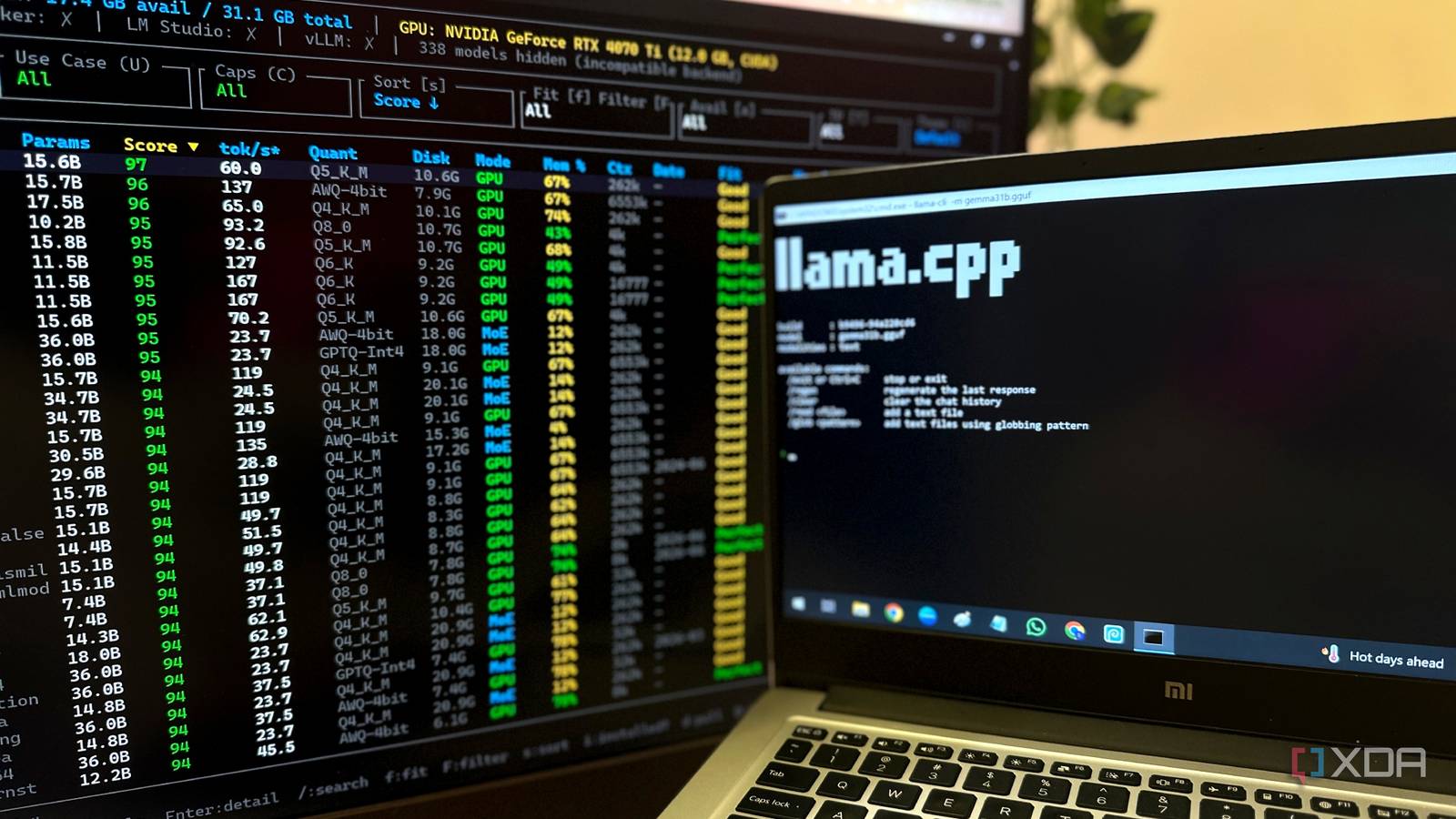
LLMFit is basically a suggestion engine for native AI fashions that makes your job rather a lot simpler in case you’re stepping into self-hosted AI. Earlier than you commit to an enormous obtain for a 10-, 15-, or 20-GB mannequin, it figures out whether or not your {hardware} can realistically deal with such a mannequin first. When you install and run it, LLMFit will consider your CPU, GPU, and obtainable RAM and VRAM earlier than rating over 250 fashions in line with how nicely they’re going to carry out in your machine.
The star of the present right here is the “Match” rating, which rolls pace, context size, and high quality all into one to attain a mannequin out of 100 factors. So, as a substitute of forcing you to decipher pages of benchmarks, it will provide you with a sensible shortlist of fashions which are truly value your time. Certain, in case you’re sitting on a workstation with sufficient VRAM to make enterprise AI labs blush, you may haven’t any scarcity of choices anyway, however for the remainder of us working throughout the confines of shopper {hardware}, that is precisely the type of drawback LLMFit exists to resolve.
It does not cease at suggestions, both. LLMFit integrates instantly with Ollama and llama.cpp, so as soon as you’ve got discovered a mannequin that matches the invoice, you’ll be able to launch it with out bouncing between completely different purposes. Alongside every suggestion, there’s one thing significantly useful for newcomers, which is a workload label — the software tells you whether or not a mannequin you are eyeing is greatest suited to coding, chat, picture technology, or MoE (combination of consultants) duties. That instantly interprets into much less time Googling mannequin names, and extra time truly utilizing them.
I ran native AI fashions on a six-year-old laptop computer with no GPU, they usually truly labored
Your outdated laptop computer is highly effective sufficient for native AI… in case you mood expectations
set up LLMFit in your Home windows gadget
Simply three instructions to get began
To put in LLMFit in your gadget, the very first thing you want on a Home windows machine is Scoop. Scoop is a well-trusted command-line installer for Home windows. To put in Scoop, merely paste the next line of code into an elevated PowerShell window:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
Right here, odds are you may both see no response and the command will work correctly, or PowerShell will ask you if you wish to change the execution coverage. Press Y and hit Enter. Copy the following line into the identical window:
Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression
This may set up Scoop in your Home windows gadget. The subsequent factor it’s essential do is to open a Command Immediate window and easily sort within the following:
scoop set up llmfit
With that, LLMFit is put in in your gadget. Simply sort in llmfit right into a CMD or PowerShell window, and it’ll instantly pop up with all its information on native AI fashions you can set up and run in your gadget.

Native LLMs weren’t sufficient, so I take advantage of a two-tier system that retains my delicate stuff offline
Personal information stays native, smarter AI comes later.
I examined LLMFit on a six-year-old laptop computer
It instructed me precisely which mannequin labored greatest

As soon as I put in LLMFit on my six-year-old laptop computer, it shortly detected the {hardware} and listed fashions that it thought would work greatest on it. That is an outdated Mi laptop computer purchased in 2019, with all of 8GB RAM, and an Intel i5-10210U CPU working at 1.60 GHz. Within the graphics division, it is acquired nothing to boast aside from Intel UHD built-in graphics. Even on this outdated piece of {hardware}, LLMFit solely took a handful of seconds to be up and working after it detected my gadget’s capabilities.
LLMFit is a keyboard-only software. It operates operates like an outdated motherboard BIOS interface.
LLMFit gave Microsoft’s Phi-mini-MoE-instruct mannequin a powerful 90.4 out of 100 on the composite rating, itemizing it on the very high of the record for what would run greatest. The software estimated that I’d get round 40-42 tokens per second working this 7.6B-parameter mannequin in llama.cpp, so I instantly downloaded the precise quantization LLMFit advised (Q4_K_M).
Fortunately, there’s the choice to obtain a mannequin instantly from the software itself, and with the press of the “d” key, I instantly downloaded the AI mannequin from Hugging Face. After I ran it, I did not fairly get the tokens and pace LLMFit promised, nevertheless it was nonetheless within the 20-25 token-per-second class.
The issue, nevertheless, got here once I took a more in-depth have a look at the laundry list of AI models contained in the software. Quite a lot of these fashions listed are outdated and out of date already, which instantly signaled to me that the app requires far more fashions up to date into it and with way more frequency. As a stepping stone, nevertheless, I do not see the draw back to putting in LLMFit and utilizing it along with your {hardware} to get a lay of the land earlier than downloading large AI fashions to make use of domestically.
My native LLM can name Claude when it is caught, and it modified every little thing about my local-first setup
Native LLMs aren’t excellent on their very own
Ought to everybody utilizing native AI fashions use LLMFit?
Till you find out how parameter counts and quantizations have an effect on your {hardware}, LLMFit removes a lot of the trial and error.
For me, LLMFit is greatest considered as a stepping stone fairly than a software you may depend on perpetually. It solely takes just a few weeks of experimenting with native AI earlier than you develop a great really feel to your personal {hardware}. When you find out how parameter counts, quantizations, and reminiscence necessities have an effect on efficiency, you may additionally begin making educated guesses your self. Till you attain that time, although, having a software that removes a lot of the trial and error is genuinely precious. It provides you the boldness to obtain fashions realizing there is a good probability they’re going to carry out the best way you anticipate.
That grew to become particularly clear once I helped a buddy dip their toes into native AI on an Acer Nitro 5 with an RTX 3050 Laptop computer GPU. We did not need to obtain infinite fashions and undergo all of them to see which labored greatest. LLMFit simply instantly surfaced fashions that made sense for the {hardware} and paired completely with Ollama, llama.cpp, and different self-hosted entrance ends. Greater than something, although, it smooths out these first few self-hosting adventures, changing frustration with momentum and serving to newcomers construct a stable basis with out losing hours on fashions that had been by no means going to run nicely within the first place.