


AI benchmarks will be unbelievable instruments, however they normally solely let you know if a mannequin handed or failed. With ARC-AGI-3, nonetheless, we will see the thought course of behind the rating, not simply the end result.
This week we went by 160 replays and reasoning traces from OpenAI’s GPT-5.5 and Anthropic’s Opus 4.7 trying novel, long-horizon environments. The scores had been only one knowledge level, however the attention-grabbing story is how they achieved their rating.
At this time we’re open-sourcing our evaluation bundle.
| Mannequin | ARC-AGI-3 Rating* | Public Demo Replays |
|---|---|---|
| GPT-5.5 | 0.43% | Link |
| Opus 4.7 | 0.18% | Link |
* Scores examined with the semi-private dataset
With ARC-AGI-3 we will replay each motion alongside the mannequin’s reasoning to see the place it fashioned a speculation, the place it deserted an accurate one, the place it locked onto a fallacious thought and could not let go.
We discovered 3 frequent failure modes:
- True Native Impact, False World Mannequin – The fashions perceive which motion produced a change, however they fail to translate the impact into a worldwide rule
- Fallacious Stage of Abstraction From Coaching Information – The fashions mistake an ARC-AGI-3 atmosphere for one more sport
- Solved The Stage, Didn’t Study The Recreation – Even when a mannequin beat a degree, it’s unable to make use of that reward sign to implement the proper actions
ARC-AGI-3 as an evaluation software
ARC-AGI-3 is a collection of 135 novel environments. Every was hand-crafted by a human to check the power of AI fashions to adapt to novelty. Play them your self or watch our launch video.
The test-takers, whether or not human or AI, are not given directions on tips on how to play an atmosphere. To make progress they have to:
- Discover unfamiliar interfaces
- Infer guidelines from sparse suggestions (aka world mannequin)
- Type & check hypotheses
- Recuperate from fallacious assumptions
- Switch what they realized from one degree to the subsequent (aka continuous studying)
Every atmosphere is constructed with out the cultural data a mannequin would normally lean on. This implies the environments isolate summary reasoning.
You possibly can consider ARC-AGI-3 because the lowest frequent denominator throughout novelty, ambiguity, planning, and adaptation. These are the identical calls for real-world duties make of brokers.
ar25, lf52, sb26Failure modes on ARC-AGI-3
ARC-AGI-3 was constructed with testing and mannequin auditing in thoughts. Every AI run is recorded together with its reasoning traces. We’ve had over 1,000,000 games performed on ARC-AGI-3 to this point.
For this evaluation we:
- Obtain all of the logs/reasoning/steps from each public sport run for GPT-5.5 and Opus 4.7
- Write a technique for every sport to function our floor fact reply
- Ask Codex/Claude Code to investigate the reasoning steps towards the extent technique to search out failure modes
- Do a meta-analysis throughout video games for a single mannequin. Repeat the meta-analysis throughout fashions.
- Validate findings, by hand, with a human
This led us to find why every mannequin handed/failed, which failure modes had been shared and which had been distinctive to every mannequin.
Failure mode 1: true native impact, false world mannequin
The primary failure mode we noticed was essentially the most dominant sample. Fashions had been capable of understand an area impact:
After I press ACTION3, this object rotates.
however they weren’t capable of translate that right into a world mannequin:
ACTION3 rotates the item, and rotation controls which facet will get a brand new worth, so I ought to orient the item to match the goal earlier than performing.
Put one other method, the fashions don’t fail as a result of they don’t observe something…they fail as a result of they cannot anchor their statement in a world mannequin.
For instance, Opus, when taking part in cd82, knew that ACTION3 rotated the container by step 4, and by step 6 it noticed ACTION5 pour/dip paint however it by no means transformed that into “orient bucket, then dip to recreate the top-left goal.”

Opus 4.7 Playing
cd82. Recreation Rating: 0%Or in cn04, Opus discovered a profitable rotate-then-place interplay (that is the proper speculation, step 23) however optimized for whole-shape overlap (incorrect) and pretend top-row progress (step 60).

cn04. Recreation Rating: 0%Failure mode 2: fallacious degree of abstraction from coaching knowledge
The second failure mode got here from an incorrect degree of abstraction from a mannequin’s coaching knowledge. Throughout the runs, the fashions repeatedly defined unfamiliar mechanics by mapping them to recognized video games: Tetris, Frogger, Sokoban, Powder Toy, Flood-It, MiniGrid, CoinRun, Breakout, Pong, Boulder Sprint, and others. Whereas recalling abstractions from core prior data is useful in principle, the literal analogies from the mannequin’s coaching knowledge hijacked motion choice.
The issue is {that a} native visible resemblance turns into a full gameplay principle, then the mannequin wastes actions testing the fallacious affordances.
In cd82, GPT-5.5 anchored on sand/physics/Flood-It mechanics. ls20 turned Breakout as a substitute of key combos.

ls20 for different video games. GPT-5.5 Playing ls20. Recreation Rating: 0%Failure mode 3: solved the extent, didn’t study the sport
The ultimate failure mode we noticed was that even when a mannequin beat a degree, that reward did not translate into additional success. This reveals us that beating a degree isn’t the identical as understanding it.
Two Opus runs make this particularly clear. On ka59, Opus solved Level 1 in 37 actions, however its working principle of the clicking (teleporting the lively character) was fallacious. Though it appeared like a clear win, this was a coincidence between a misinterpret primitive and a forgiving degree.
When Stage 2 demanded the actual mechanic (shape-matching and pushing), Opus’s mislabel principle hardened into “click each target to fill it,” and the run by no means recovered.

ka59. Recreation Rating: 2.04%ar25 reveals the identical sample at a special abstraction degree. Opus cleared Stage 1 with an accurate learn of mirrored motion (step 4), then in Stage 2 really found the brand new movable-axis mechanic (step 227), however it nonetheless drifted into hallucinated guidelines of punching holes and needing a flip.
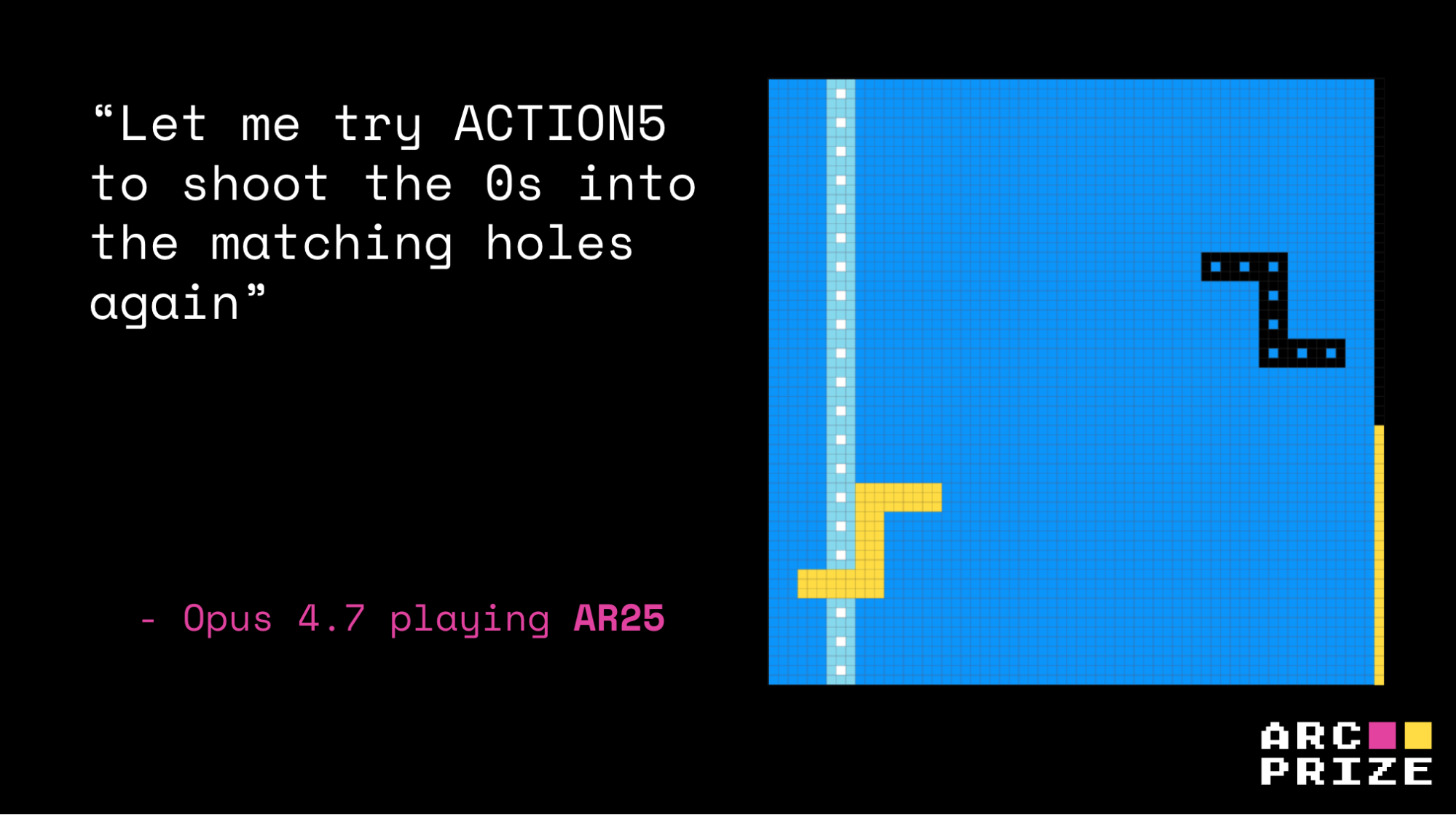
ar25. Recreation Rating: 0.15%In each circumstances the Stage 1 success masked a lacking or distorted primitive, and the partial win turned a assured scaffold for the fallacious Stage 2 technique.
This additionally reveals us that early degree development generally is a noisy sign of comprehension. With out an specific test on why the prior degree was gained, fashions will carry their false impression into the subsequent degree.
Opus 4.7: fallacious compression, GPT-5.5: failure to compress
As we examine the runs of GPT-5.5 and Opus 4.7 we’re capable of see they failed in completely different methods. That is essential as a result of combination scores alone would disguise this distinction.
Opus had the fallacious compression, GPT-5.5 didn’t compress.
Opus 4.7 is stronger at short-horizon mechanic discovery. On ar25 it identifies the mirror construction virtually instantly and clears Stage 1. On ka59 it reads the two-character, two-target format and executes the brief Stage 1 sequence even with an incomplete world mannequin.
The flipside is that Opus can be extra more likely to latch onto a false invariant and execute it aggressively. On cn04 it leans right into a faux progress/timer/conversion principle and spends the opener click-fishing inside that story (step 60). It does kind a working principle, it is simply the fallacious one.
GPT-5.5 sits on the different finish. Its speculation technology is wider, which makes it extra more likely to articulate the precise thought however much less more likely to flip it right into a plan. On ar25 it names the mirror impact however retains reopening the style house, drifting by Tetris, Frogger, Pong, and Tower of Hanoi as a substitute of committing to reflection. On ka59 it reaches the proper object ontology, two goal outlines and a switchable second character, however by no means commits to it.
The distinction comes all the way down to compression. Opus compressed its observations right into a confident-but-wrong principle. GPT-5.5 had issue compressing in any respect.
ARC-AGI-3 measures agent autonomy
Every ARC-AGI-3 atmosphere has been solved by at least two humans with out particular coaching. What makes them onerous for brokers is that they require one thing nearer to actual intelligence by encountering an unfamiliar atmosphere, forming a working principle, testing it, updating it when the proof disagrees, and carrying ahead what was realized.
That very same degree of meta-learning can be what real-world brokers will want.
Actual-world brokers won’t simply function inside clear benchmark prompts or memorized job templates. They may face unfamiliar web sites, inner instruments, dashboards, kinds, APIs, workflows, and edge circumstances that weren’t described prematurely. In these settings, failure will typically look precisely just like the failure modes in ARC-AGI-3.
That is why ARC Prize Basis will proceed auditing each main frontier launch. Scores let you know what a mannequin achieved. Replays let you know whether or not or not the reasoning is more likely to generalize.
For those who’d like to assist us audit the frontier of AI with ARC-AGI-3, come join the team.
Evaluation notes
- With our default exams, GPT-5.5 didn’t return its reasoning traces. The qualitative evaluation above subsequently makes use of an
evaluation moderun, which is an alternate testing setup meant to elicit extra specific descriptions of how the mannequin is deciphering the atmosphere and deciding what to attempt subsequent. The official GPT-5.5 rating isn’t from that mode. All reported scores use the usual ARC-AGI-3 harness, matching the setup used for Opus 4.7.